RHCA概述
## 概述
1. RH442 红帽的Linux性能调优
2. CL260 RHCS ceph的云存储
3. RH358 服务自动化 使用ansible来管理服务
4. D0447 ansible平台自动化
5. CL210 OSP 红帽的云计算平台 开源的openstack
对于环境 RHCI的培训环境 32G内存及以上
## D0447 ansible平台自动化
# RH294 (RHCE8.0中的ansible) --> D0447 ansible高级自动化
# 技能
Ansible的基础使用 ansible 命令、剧本、变量...
Ansible的平台使用 ansible tower(web) 和 gitlab 集成
Ansible的性能调优 剧本调优 主机调优 任务调优
## 红帽卫星
支持ansible,通过ansible来对主机打补丁
红帽卫星是基础架构的管理平台,可以接管主机、服务器、操作系统
## 其他厂家
华为的虚拟化: 虚拟化主机 CNA,
VMware的虚拟化: 虚拟化主机 ESXI,Venter管理ESXID0447/347 Ansible平台自动化
概述
# Ansible 的原理与安装
1. ansible是一个开源的自动化工具(GPLV3 开源)
2. ansible-tower 是一个企业级自动化平台,是统一的ansible主控管理平台。(是目前市场上除了自研以外的唯一选择方案)
3. ansible-tower 来自于开源的 AWX
自动化:当一个人不想再次解决通用的问题时,就需要自动化。
# Ansible可以几乎对所有IT资源自动化管理
编排、配置管理、应用部署、能力发放、持续交付、安全合规
防火墙、负载均衡器、应用、容器、公有/私有云、服务器、基础架构、存储、网络设备等。
# 部署一个企业网站(自建机房开始),那么ansible可以完成那些部分
基础硬件(机房、宽度、空调、服务器硬件...)
安全操作系统 # PXE+Kickstart
调试系统的配置(配置防火墙、配置存储...) # Ansible 支持
安全web软件(nginx、apache、tomcat) # Ansible 支持
安装web中间件(redis、MQTT消息队列...) # Ansible 支持
修改web的配置(nginx/apache) # Ansible 支持
发布网站的源码 # Ansible 支持
用户才能访问网站 # Ansible 支持
## 为何选择Ansible
# 简单
人工可读的自动化: ansible使用yaml语音来作为其配置
无需特殊编码技能:
任务按顺序执行:
可用于任何团队:运维、开发、测试等
支持Windows自动化: Windows只能作为ansible的被控,不能称为主控。
快速提高生产力:
# 强大
深入了解Windows PowerShell: ansible支持通过powershell来管理windows(通过vinrm来远程)
期望的状态配置(Desired State Configuration)管理: 幂等性:一次执行和多次重复执行对结果的影响是一致的。(mkdir /abc如果目录已经存在就不会执行)ansible报错了 可以从出错的重新开始执行。
域组和用户管控:
企业级应用部署: 将多个任务按照一定的逻辑或者顺序组合在一起执行。
多层部署编排:
# 无代理
无代理架构: ansible使用应用原生的方式来管理应用本身。
支持WinRM: windows原生支持的远程管理方式winrm; ssh是linux服务器自带的远程管理方式; snmp是网络设备的简单网络管理协议; 通过api管理公有云。
没有代理需要开发或更新:
即开即用:
更高效,更安全:
##
ansible对于简单的任务使用ansible ad-hoc(临时命令)来完成,对于复杂的任务使用ansible的palybook(剧本)来完成
ad-hoc: 比如创建用户、安全软件包... 通常是单个任务
playbook: 比如构建企业网站,对业务系统升级.. 通常是第一个项目
Ansible的基本组件
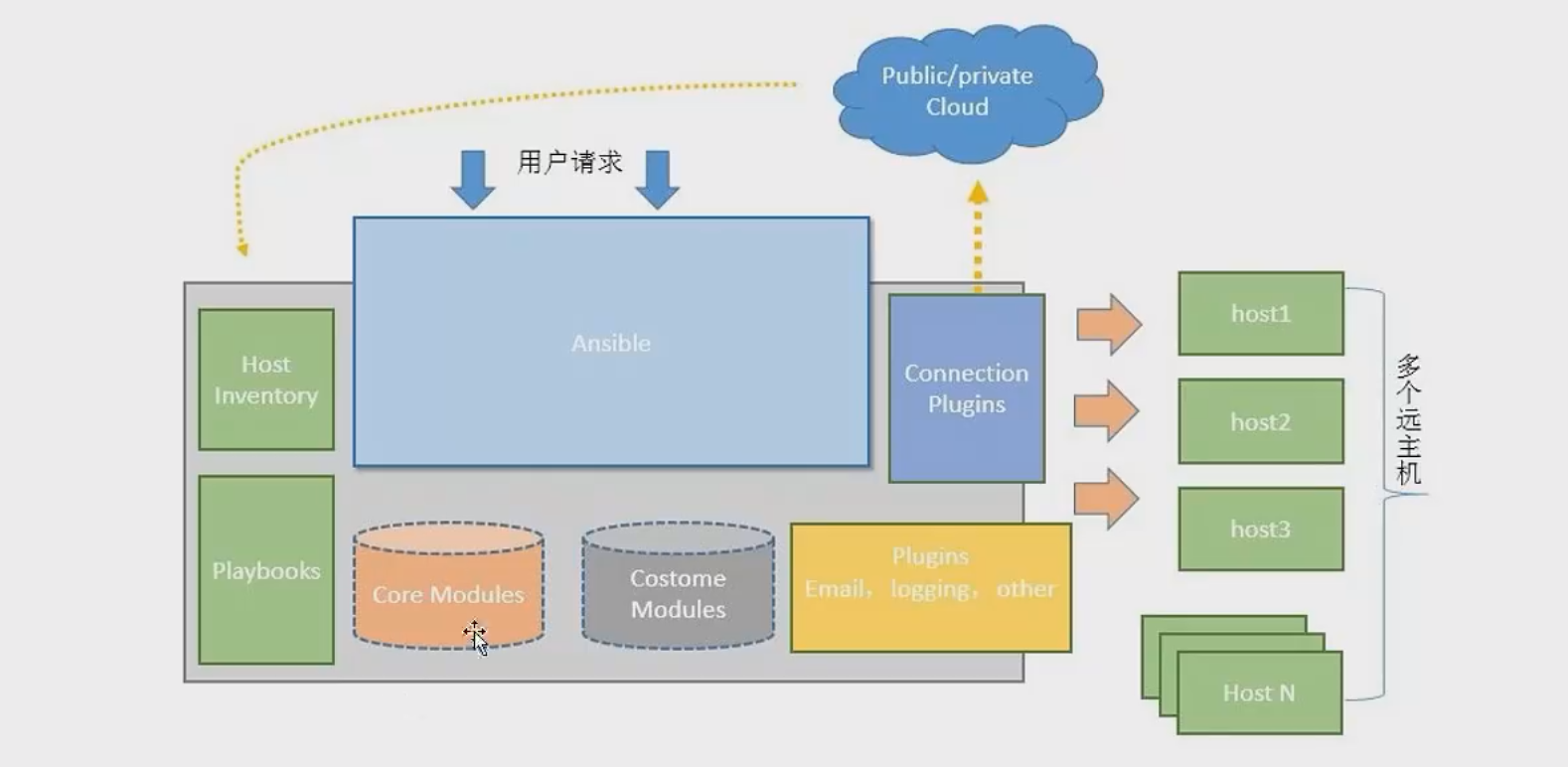
# 核心: ansible
# 核心模块(Core Modules): 这些都是ansible自带的模块
# 扩展模块(Custom Modules): 如果核心模块不足以完成某种功能,可以添加扩展模块
# 插件(Plugins): 完成模块功能的补充
# 剧本(Playbook): 把需要完成的多个任务定义在剧本中
# 连接插件(Connectior Plugins): ansible基于连接插件连接到各个主机上,虽然ansible是使用ssh连接到各个主机的,但是它还是支持其他的连接方法,所以需要有连接插件。
# 主机清单(Host Inventory): ansible在管理多台主机时,可以选择只对其中的一部分执行某些操作。Ansible工作原理
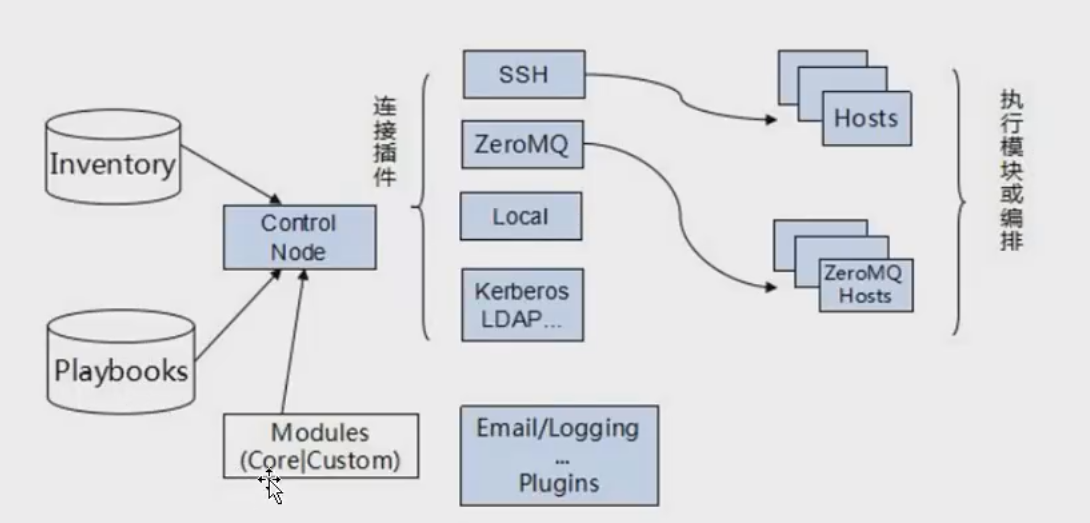
## Ansible的工作原理
1. Ansible在管理节点将Ansible模块通过SSH协议(或者Kerberos、LDAP)推送到被管理端执行,执行完之后自动删除,可以使用版本控制系统(git/svn)来管理自定义模块及playbooks
2. 解析Inventory文件(主机清单): 在Ansible执行任何任务之前,需要先解析Inventory文件以确定被管理节点的位置和角色。Inventory文件是一个文本文件,它描述了被管理节点的名称、IP地址、主机信息等。
3. SSH连接到被管理节点: Ansible使用SSH协议或WinRM协议连接到被管理节点,这取决于节点操作系统的不同。在连接时,Ansible会验证SSH密钥并启动一个临时的SSH连接进程。
4. 执行任务:连接建立后,Ansible通过模块执行任务。模块是Ansible执行每个任务的工具,如文件操作、软件包安装、服务启动等。Ansible会将任务发给所有被管理节点,并在这些节点上执行相应的操作。当任务执行完成后,Ansible会收集任务执行结果并返回控制节点。
5. 关闭连接:任务执行完成后,Ansible会关闭于被管理节点的连接,并停止SSH连接进程。
ansible只能管理清单中的主机,如果被管理的主机不在清单中,ansible不执行任务。Ansible安装
# 发行版的构建包
https://releases.ansible.com/ansible/rpm/release # 截止到epel7
# ansible的源码包
https://releases.ansible.com/ansible # 官方维护的稳定版;较开源的版本较低
https://github.com/ansible/ansible # 社区维护的开源版;版本更新较快,新特性较多
D447安装2.8的ansible版本
# python的pip源
https://pypi.org/project/ansible源码编译安装
# 下载源码包
cd /opt
https://ghproxy.com/https://github.com/ansible/ansible/archive/refs/tags/v2.8.0.zip
https://ghproxy.com # github代理
https://ghfast.top # github新代理
# 安装依赖
dnf install -y gcc libffi-devel openssl-devel python3 python3-devel python3-cryptography -y
# 执行安装
cd /opt
unzip v2.8.0.zip && cd /opt/ansible-2.8.0/
python3.6 setup.py build # 构建包,构建python可以安装的包
python3.6 setup.py install # 安装包 【安装失败执行mkdir -p /usr/local/lib/python3.6/site-packages/】
# python3.6 -m pip install "jinja2<3.0" "pyyaml<6.0" "cryptography<3.4" 报错执行该命令
# python3.6 -m pip install . # 报错执行改名了
# 生成配置文件
mkdir /etc/ansible
cp /opt/ansible-2.8.0/examples/ansible.cfg /etc/ansible/
cp /opt/ansible-2.8.0/examples/host /etc/ansible
RPM安装方式
# access.redhat.com
# vim dve.repo
[BaseOS]
name=BaseOS
baseurl=file:///dvd/BaseOS
enabled=1
gpgcheck=0
[AppStream]
name=AppStream
baseurl=file:///dvd/AppStream
enabled=1
gpgcheck=0
[ansible]
name=ansible
baseurl=file:///ansible/ansible
enabled=1
gpgcheck=0
# 安装
yum clean all && yum makecahce
yum install ansible -y
PIP安装ansible
# dvd.repo
[BaseOS]
name=BaseOS
baseurl=file:///dvd/BaseOS
enabled=1
gpgcheck=0
[AppStream]
name=AppStream
baseurl=file:///dvd/AppStream
enabled=1
gpgcheck=0
# 安装依赖
yum install rust cargo python3-cryptography -y
# 安装ansible, pip加速
pip3 install ansible==2.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 没有配置文件,需要手写
mkdir /etc/ansible
touch /etc/ansible/ansible.cfg
touch /etc/ansible/hosts
# 没有sshpass包,需要安装
rpm -ivh ./ansible-2.8-for-rhel-8-x86_64-rpms/Packages/s/sshpass-1.06-3.el8ae.x86_64.rpmAnsible主机清单
定义主机清单
# 1. ansible主机清单的位置
/etc/ansible/hosts 默认的清单位置,位置是在ansible.cfg文件中定义。
# 2. 定义主机的方式
直接在清单中写主机的主机名或者是IP地址(如果是主机名一定要被正常的解析到IP)
192.168.23.1
node1
# 3. 定义主机组, groupname自定义
[groupname1]
192.168.23.2
node2
[gruopname2]
192.168.23.3
node2
# 4. 同时定义主机和主机组:主机定义到主机组前面
192.168.23.1
[groupname1]
192.168.23.2
node2
# 5. 定义嵌套组
[p-groupname:children]
groupname1
groupname2
# 6. 使用范围来匹配主机
db[1:100].example.com # 表示连续匹配1到100台主机db1到deb100
server[a:z].example.com # 表示连续匹配a到z的主机
192.168.23.[1:10]选择主机和主机组
# 1. 匹配所有主机
ansible all --list-hosts
# 2. 匹配指定主机或者主机组
ansible ip --list-hosts
ansible groupname --list-hosts
# 3. 匹配多个主机
ansible ip,groupname --list-hosts
# 4. ungrouped 是一个特殊的组,在改组中记录了所有没有组的主机。
ansible 将系统中没有组的主机都放在ungrouped的组中进行管理。
# 5. 通配符选择主机
ansible 'server*' --list-hosts # 找到以server开头的主机
ansible '192.168.10.*' --list-hosts # 找到192.168.10网段的主机
# 6. 通配符逻辑组合选择主机
ansible 'server*,!*b' --list-hosts # 选择以server开头的主机,但不要b结尾的主机。[!是取反的意思]
ansible '!serverb' --list-hosts # 选择不是serverb的其他主机
# 7. 找到2个组中相同的主机
ansible 'groupname1,&groupname2' --list-hosts # 选择同时出现在groupname1和groupname2中出现的主机
# 8. 找到同时在group1和group2组中,不在group3组中,且在group4组中。
ansible 'group1,&group2,!group3,&group4' --list-hosts
# 9. 使用正则表达式匹配选择 '~'
ansible '~^node*' --list-hosts # 选择node开头的主机
ansible '~(node|server)' --list-hosts # 选择以node或者server开头的主机
# 10. 使用文件进行匹配, 创建一个ip.txt包含定义主机清单的信息。@后面是文件名
ansible all --limit @ip.txt --list-hsots
ansible all --limit node1,servera --list-hosts # 只需要node1,servera主机Ansible的配置
Ansible配置文件
## /etc/ansible 目录
## ansible.cfg 主配置文件
grep -Ev '^#|$^$' ansible.cfg # 只显示文件的非注释和空白行
[defaults]
[inventory]
[privilege_escalation]
[paramiko_connection]
[ssh_connection]
[persistent_connection]
[accelerate]
[selinux]
[colors]
[diff]
## hsots 主机清单文件
## roles 目录,角色存放的位置
ansible.cfg 主配置文件
## [defaults]
通用配置项
#inventory = /etc/ansible/hosts
主机清单存放目录
#library = /usr/share/my_modules/
模块知识库存放目录
#module_utils = /usr/share/my_module_utils/
扩展模块存放目录
#remote_tmp = ~/.ansible/tmp
远程在被控端的临时存放目录
#local_tmp = ~/.ansible/tmp
本地的临时文件存放目录
#plugin_filters_cfg = /etc/ansible/plugin_filters.yml
使用filters插件的配置文件
#forks = 5
并发数,大规模场景下
#poll_interval = 15
#sudo_user = root
提权的用户
#ask_sudo_pass = True
提权时是否需要密码
#ask_pass = True
连接被管理端时是否需要密码
#transport = smart
#remote_port = 22
远程的端口
#module_lang = C
自定义的模块编程语言
#module_set_locale = False
#host_key_checking = False
第一次使用ssh连接时是否会问yes or no, 是否同意对方的主机指纹
如果取消注释,就不用输入yes or no,一般取消注释
#timeout = 10
ssh 超时时间
#remote_user = root
远程的用户,使用什么用户连接到被控端
#module_name = command
ansible执行命令的默认模块名称
## [inventory]
#enable_plugins = host_list, virtualbox, yaml, constructed
指定主机清单的形式
主机清单支持的插件,还支持动态清单等【yaml文件,virtualbox虚拟机,脚本,阿里云账号的服务器】
#ignore_extensions = .pyc, .pyo, .swp, .bak, ~, .rpm, .md, .txt, ~, .orig, .ini, .cfg, .retry
忽略一些文件的后缀
## [privilege_escalation] 配置提权的选项
#become=True
开启提权,在生产环境中,如果等保要求,不可以使用root直接登录。运维账号通常是普通账号,所以需要提权到root执行命令。
#become_method=sudo
提权方式,ansible原生支持2种方式,默认su, 还支持sudo。
#become_user=root
提权到root账号权限
#become_ask_pass=False
提权是否需要验证密码,False是免密提权
## [paramiko_connection] 早期RHEL6以前使用的连接方式
红帽6以前保留的配置,需要配置python-openssh的包,是通过python来执行ssh的
从RHEL7开始使用openssh来进行连接
## [ssh_connection] SSH配置项
#ssh_args = -C -o ControlMaster=auto -o ControlPersist=60s
连接的参数,是否需要开启启动压缩,设置长连接时间。
性能调优会使用到该选项
# control_path_dir = /tmp/.ansible/cp
临时文件的释放目录
#control_path_dir = ~/.ansible/cp
控制文件的释放目录
## [persistent_connection] 长连接的配置【持久连接】
#connect_timeout = 30
一个任务的超时时间是30秒
#command_timeout = 30
一个命令的超时时间是30秒
## [accelerate] 加速连接的配置【SSH连接有性能瓶颈,1000台服务器连接开销很大,保持连接,一个一个执行】
可以采用消息队列的方式,将所有任务全部发送到被控端,在被控端执行结果异步同步到主控端。【发送到被控端让被控端去执行任务】
性能调优项
#accelerate_port = 5099
#accelerate_timeout = 30
#accelerate_connect_timeout = 5.0
#accelerate_daemon_timeout = 30
## [selinux] selinux的配置
#special_context_filesystems=nfs,vboxsf,fuse,ramfs,9p
允许ansible去操作文件系统类型。
#libvirt_lxc_noseclabel = yes
能否操作lxc容器
## [colors] ansible回显给用户的颜色
#highlight = white
#verbose = blue
#warn = bright purple
#error = red
报错信息显示为红色
#debug = dark gray
#deprecate = purple
#skip = cyan
#unreachable = red
#ok = green
目标期待值一样就绿色
#changed = yellow
命令执行成功产生影响显示黄色
#diff_add = green
#diff_remove = red
#diff_lines = cyan
## [diff] 差异比较
# always = no
# context = 3ansible配置文件优先
# ansible 配置文件存放的4个位置
1. ANSIBLE_CONFIG 的环境变量【优先级1】
2. 当前工作目录下的ansible.cfg【优先级2】
3. 当前用户家目录下的.ansible.cfg 隐藏文件【优先级3】
4. 全局默认的配置文件 /etc/ansible/ansible.cfg【优先级4】
配置案例001
## 配置node0主控管理node1被控
# 1. 在主机清单中定义被管理节点
# 2. 修改ansible.cfg的配置
[default]
inventory = /etc/ansible/hosts # 主机清单的位置
ask_pass = false # false表示密钥验证,true密码验证
remote_user = usera # 表示使用usera来ssh管理被控(远程用户)
log_path = /var/log/ansible.log # 指定ansible的日志文件位置
host_key_checking = False # 第一次连接被控主机不需要检查ECDSA的主机公钥,信任密钥 ~/.ssh/known_hosts
private_key_file = ~/.ssh/id_rsa # 指定私钥地址
[privilege_escalation]
become=True # 开启提权
becom_method=sudo # 提权的方式sudo
become_user=root # 提权到root
becom_ask_pass=False # 提权不需要密码
[ssh_connection]
ssh_args= -C -o ControlMaster=auto -o ControlPersist=60s -o StrickHostKeyChecking=no # ssh的加速连接
# 免密登录备注:
1、ssh-keygen # 需要在控制节点生成密钥。
2、ssh-copy-id usera@node1 # 将密钥拷贝到被控端
3、AuthorizedKeysFile .ssh/authorized_keys # 在被控端取消sshd配置文件的注释,允许密钥登录。
4、usera ALL=(ALL) NOPASSWD:ALL # 在被控端设置usera用户免密登录
# 3. 使用ping模块测试管理的连通性
ansible node1 -m ping
# 总结
主控:写主机清单,编写ansible.cfg的配置文件,
被控:配置用户、配置用户密码、配置sudo提权、配置用户免密登录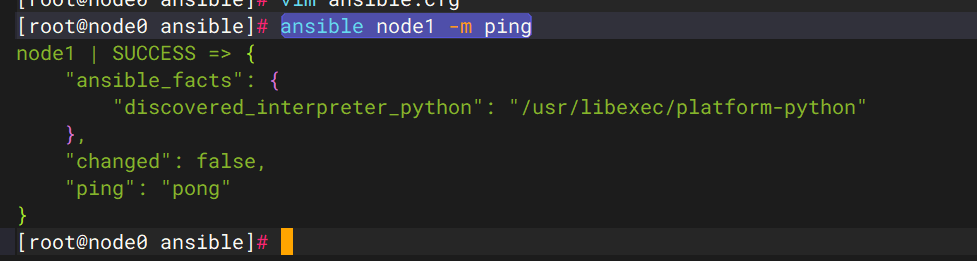
Ansible Ad-hoc 临时指令
概述
AD-hoc是指ansible下临时执行的一条命令,对于复杂的命令会使用playbook。Ad-hoc的执行依赖于模块,ansible官方提供了大量的模块。如: command, raw, shell, file, cron等。【Ad-hoc的原理就是使用ansible的模块来完成自动化任务】
# 帮助查询
ansible-doc -l # 列出ansible支持的所有模块
ansible-doc -s yum # 查看yum模块module支持的参数
ansible-doc yum # 搜索/EXAMPLES查看模版module实例AD-hoc格式
## AD-hoc命令格式
# ansible帮助查询
ansible --help
ansible --help | grep user
# AD-hoc的格式:ansible 主机/主机组 -m 模块名 -a '模块参数' ansible的参数
# ansible host/group -m module -a 'module_args' ansible_args
ansible node1 -m ping -u root -k # 配置案例001的作用, -k 是密码认证, -m ping是ping模块, -u root 指定远程的用户
ansible all -m ping -u root -k
ansible all -m ping -u root -k --become-user zhangsan # --becom-user 指定提权的账号是zhangsan
ansible all -m ping -u root -k --ask-pass=root_pass
# 创建账号, AD-hoc的格式:ansible 主机/主机组 -m 模块名 -a '模块参数' ansible的参数
ansible node1 -m user -a 'name=zhangsan' -u root -k
# 删除命令
ansible node1 -a 'rm -rf /tmp/test.txt' # -a 的''参数里面不可以使用*通配符,因为默认使用时command模块,不支持*通配符
ansible node1 -m shell -a 'rm -rf /tmp/*.txt' # 添加了shell模块就支持shell命令了、
## 其他
# ansible.cfg
host_key_checking = False
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=60s -i /root/.ssh/id_rsa
命令执行模块 module_name
## ansible的命令执行模块: command, shell, raw, script, 默认执行模块是 command
如果需要修改默认的执行命令模块,可以在ansible.cfg中修改 module_name=shell
## 1 command模块
该模块通过-a跟上要执行的命令可以直接执行,不过命令里如果有带有如下字符部分则执行不成功
"<", ">", "|", "&", "*"
# 实例
ansible node1 -a 'rm -rf /tmp/test.txt' # -a 的''参数里面不可以使用*通配符,因为默认使用时command模块,不支持*通配符
## 2 shell模块【推荐】
用法基本和commmand一样,不过是通过/bin/sh进行执行,所以shell模块可以执行任何命令,就像在本机执行一样。
# 实例
ansible node1 -m shell -a 'rm -rf /tmp/*.txt' # 添加了shell模块就支持shell命令了
ansible node1 -m file -a 'path=/opt/a.txt state=absent' # 告警的解决方法
ansible node1 -m shell -a 'chdir=/tmp touch test.txt' # 指定命令执行的目录
# 选项
free_form: 要执行的linux指令
chdir: 在执行指令之前,先切换到该指定的目录,默认工作目录是远程主机的家目录
creates: 一个文件名,当该文件存在,则该命令不执行
removes: 一个文件名,当该文件不存在,则该命令不执行
## 3 raw模块【网络设备场景|老的操作系统】
用法和shell模块一样,也可以执行任意命令,就像在本机执行一样,和command、shell模块不同的是其没有chdir、creates、removes参数
## 4 script模块
将管理端的shell在被管理主机上执行,其原理是先将shell内容复制到远程主机,再在远程主机上执行。
原理:将脚本的的内容拷贝到被控端执行
# 实例
ansible node1 -m script -a 'shell.sh'
## 其他
# 补充1:在使用ansible模块时,如果出现告警信息一般是操作的命令与使用的模块不是最匹配的。
# 补充2:关闭告警信息回显, ansible.cfg
command_warnings=Falsefile模块
## file模块主要用于远程主机上的文件操作,file模块包含如下选项:
# path: 必选项,定义文件/目录的路径
# state:
file: 查看文件状态,默认选项,若文件不存在,也不好被创建,会报错文件不存在
ansible all -m file -a 'path=/tmp/test/a.txt state=file'
touch: 如果文件不存在,则会创建一个新的文件,如果文件或目录已存在,则更新时间戳
ansible all -m file -a 'path=/tmp/test/a.txt state=touch'
absent: 删除目录、文件或者取消链接文件
ansible all -m file -a 'path=/tmp/test/a.txt state=absent'
directory: 如果目录不存在,创建目录
ansible all -m file -a 'path=/tmp/test state=directory'
link: 创建软链接
ansible all -m file -a 'src=/tmp/test.txt dest=/tmp/hello.txt state=link'
hard: 创建硬链接
ansible all -m file -a 'src=/tmp/test.txt dest=/tmp/helloword.txt state=hard'
owner: 定义文件/目录的属主
group: 定义文件/目录的属组
mode: 定义文件/目录的权限
ansible all -m file -a 'path=/tmp/test/owner.txt owner=root group=root mode=766 state=touch'
src: 要被链接的源文件的路径,只能应用于state=link的情况
dest: 被链接到的路径,只应用于state=link的情况
force: 需要在两种情况下强制创建软链接,一种是源文件不存在但之后会建立的情况下;
另外一种是目标软链接已存在,需要先取消之前的软链,然后创建新的软链,有两个选项: yes | no
ansible all -m file -a 'src=/tmp/test.txt dest=/tmp/hello.txt state=link force=yes'copy模块
## 复制文件到远程主机,copy模块包含如下选项
# src: [主控端src]要复制到远程主机的文件在本地的地址,可以是绝对路径,也可以是相对路径。如果路径是一个目录,它将递归复制。在这种情况下,如果路径使用'/'来结尾,则只复制目录里的内容,如果没有使用'/'来结尾,则复制目录本身,类似于rsync
touch /tmp/test/file{1..10}.txt # 在主控端创建
ansible all -m copy -a 'src=/tmp/test/ dest=/tmp/tmp' # 将主控端的/tmp/test目录下的内容拷贝到被控端的/tmp/tmp目录下
ansible all -m copy -a 'src=/tmp/test dest=/tmp/tmp' # 将主控端的/tmp/test目录拷贝到被控端的/tmp/tmp目录下
# dest: [必选项,被控端dest] 要将源文件复制到的远程主机的绝对路径。
# force: 如果目标主机包含该文件,但内容不同,如果设置为yes,则强制覆盖,如果为no,则只有当目标主机的目标位置不存在该文件时,才复制。默认为yes强制覆盖
ansible all -m copy -a 'src=file1.txt dest=/tmp/tmp/ force=no'
# backup: 在覆盖之前将原文件备份,备份文件包含时间信息。有两个选项: yes | no
ansible all -m copy -a 'src=file1.txt dest=/tmp/tmp/ backup=yes'
# content: 用于替代 "src", 可以直接设定指定文件的值
ansible all -m copy -a 'content='hello' dest=/tmp/tmp/file1.txt backup=yes'
# others: 所有的file模块里的相关文件属性选项都可以在这里使用
ansible all -m copy -a 'content='hello' dest=/tmp/tmp/file3.txt owner=root group=root mode=700'
# remote_src: 复制远程主机的文件
ansible all -m copy -a 'src=/root/anaconda-ks.cfg dest=/tmp/tmp remote_src=yes'yum_repository模块
ansible-doc -l | grep yum
ansible-doc yum_repository
/EXAMPLES
## 使用 yum_repository 管理yum仓库,其选项有:
# file: 配置文件的名字,不包含.repo
# name: yum仓库的名字
# description: 仓库的描述信息
# baseurl: yum源地址
# enabled: 是否开启yum仓库, yes/no
# gpgcheck: 是否检查软件包的完整性, yes/no
# gpgkey: 公钥地址
## 实例
ansible node1 -m yum_repository -a 'file=media name=BaseOS description=BaseOS baseurl=file:///media/BaseOS enabled=yes gpgcheck=yes gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release'
ansible all -m yum_repositroy -a 'file=ansible name=BaseOS description=BaseOS baseurl=file:///media/BaseOS enabled=yes gpgcheck=yes gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release'
# 2403 x86 在线默认实例 /etc/yum.repos.d/kylin_x86_64.repo
[ks10-adv-os]
name = Kylin Linux Advanced Server 10 - Os
baseurl = https://update.cs2c.com.cn/NS/V10/V10SP3-2403/os/adv/lic/base/$basearch/
gpgcheck = 1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-kylin
enabled = 1
[ks10-adv-updates]
name = Kylin Linux Advanced Server 10 - Updates
baseurl = https://update.cs2c.com.cn/NS/V10/V10SP3-2403/os/adv/lic/updates/$basearch/
gpgcheck = 1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-kylin
enabled = 1
[ks10-adv-addons]
name = Kylin Linux Advanced Server 10 - Addons
baseurl = https://update.cs2c.com.cn/NS/V10/V10SP3-2403/os/adv/lic/addons/$basearch/
gpgcheck = 1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-kylin
enabled = 0yum模块
## 使用yum包管理来管理软件包,其选项有:
# name: 要进行操作的软件包名字,也可以传递一个url或者一个本地的rpm包的路径
# state: 状态(present安装, absent协助,latest最新版本)
## 使用示例
ansible node1 -m yum -a 'name=httpd state=latest'
ansible node1 -m yum -a 'name="*" state=latest'
ansible node2 -m yun -a 'name=vsftpd state=absent'
ansible node3 -m yum -a 'name="@Development Tools" state=present'Service模块
【红帽7及以下版本推荐使用】
## 用于管理服务,该模块包含如下选项:
# name: 必选项,服务名称
# state: 对当前服务执行(started,stopped,restarted,reloaded)等操作
# enabled: 是否开启启动 yes | no
## 使用示例
ansible node1 -m service -a 'name=httpd state=started enabled=yes'System模块
【红帽8及以上版本推荐使用】
## 用于管理模块,该模块包含如下选项
# name: 指定服务名称
# state: 管理服务状态(reloaded|restarted|started|stopped)
# enalbed: 是否设置开机自启
# daemon_reload: 当服务配置文件发生变更使重载服务
## 使用示例
ansible node1 -m systemd -a 'name=httpd state=started enabled=yes daemon_reload=yes'cron模块
## 用于管理计划任务,包含如下选项
# name: 该任务的描述
# state: 确认该任务计划是创建还是删除,present创建,absent删除
# user: 以哪个用户身份执行
# day: 日(1-31,,/2,...)
# hour: 小时(0-23,,/2,...)
# minute: 分钟(0-59,,/2,...)
# month: 月(1-12,,/2,...)
# weekday: 周(0-7,*,...)
# job: 要执行的任务,依赖与state=present
# cron_file: 指定配置文件,例如/etc/crontab, /etc/cron.d/*
## 示例
# 默认存放路径/var/spool/cron/root, root是执行用户名
ansible all -m cron -a 'name="ansible name" minute="*/3" job="echo hello" state=present'
# 指定cron_file同时需要指定user, cat /etc/crontab 【推荐】
ansible all -m cron -a 'name="ansible name" minute="*/3" job="echo hello" state=present cron_file=/etc/crontab user=root'
# 删除
ansible all -m cron -a 'name="ansible name" state=absent' #默认删除/var/spool/cron/root下的
ansible all -m cron -a 'name="ansible name" state=absent cron_file=/etc/crontab user=root' # 路径需要指定删除才可以
user模块
## user模块请求的时useradd, userdel, usermod三个指令
# state: 是创建还是删除
# name: 指定用户名
# uid: 指定用的uid
# group: 指定用户属组
# groups: 指定用户的附加组
# comment: 定义用户描述信息
# create_home: 是否创建家目录 yes | no
# home:指定用户的家目录,需要与create_hoome配合使用
# shell: 指定用户的shell环境
# password: 指定用户的密码
# remove: 当state=absent时,remove=yes则表示连同家目录一起删除,等价与userdel -r
## 实例
# 创建账号
ansible all -m user -a 'name=lisi uid=2000 group=zhangsan groups=student comment="mysql user" create_home=yes home=/lisi shell=/sbin/nologin password="$6$1LwPLoxZvyrOD8Ez$KQ5GVlYH7WJaBeDTmPT3LSBlBYBgzQ8CjPaGtOYcc8i6LkHctDHdNGTZmdDMH.8DfxCU96pGD7FOQFJk3I5E70" state=present'
# 更新账号-密码
ansible all -m user -a 'name=lisi password="$6$1LwPLoxZvyrOD8Ez$KQ5GVlYH7WJaBeDTmPT3LSBlBYBgzQ8CjPaGtOYcc8i6LkHctDHdNGTZmdDMH.8DfxCU96pGD7FOQFJk3I5E70"'
# 删除账号
ansible all -m user -a 'name=lisi remove=yes state=absent'
# 检查
id lisi # 查看uid, gid, groups
grep lisi /etc/passwd # 查看comment, create_home, shell
ls /lisi # 查看家目录
ls -ll /var/spool/mail/ # 查看邮件地址
# 密码加密
openssl passwd -6 Kylin@123 # 对Kylin@123加密,使用SHA512加密(-6)
grep root /etc/shadow # 查看root默认就是使用SHA512加密的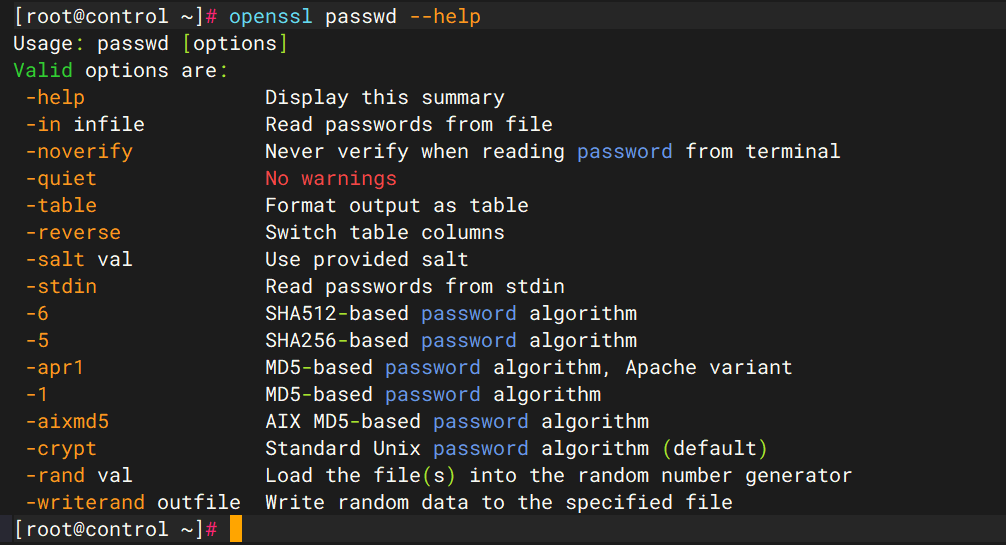
group模块
## group模块请求的是useradd, groupdel, groupmod三个指令
# gid: 制定组id
# name: 指定组名
# state: 创建还是删除组,选项: present|absent
## 使用实例
ansible node1 -m group -a 'name=test gid=1001 state=present'
# 检查
cat /etc/groupfetch模块
巡检常用该模块
## fetch模块与copy模块正好相反,copy是把主控端的文件复制到被控端,而fetch则是把被控端的文件复制到主控端。并且在主控端指定的目录下,以被控端主机名的形式来组织目录结果。常用选项有:
# src: 被控端要复制的文件地址,只能是文件,不能是目录
# dest: 主控端存放文件的地址
# flat: 默认为no, 表示在主控端目录下以被控端主机名的形式来组织目录结构。yes表示不会以被被控端主机的形式来组织目录结构,dest必须以/结尾。[不加/可能因为是重命名文件]
## 使用示例
ansible node1 -m fetch -a 'src=/etc/shadow dest=test'
ansible node2 -m fetch -a 'src=/etc/shadow dest=test/ flat=yes'get_ulr模块
## 该模块用于从http, ftp, https服务器上下载文件(类似于wget), 主要有如下选项:
# url: 下载的URL
# url_password, user_username: 主要用于需要用户名密码进行验证的情况
# dest: 目标目录
# mode: 权限
# owner: 拥有人
# group: 拥有组
## 使用示例
ansible node1 -m get_url -a 'user=https://mirrors.aliyun.com/centos/8/BaseOS/x86_64/os/Packages/samba-4.9.1-8.el8.x86_64.rpm dest=/tmp/samba.rpm owner=student group=devops mode=0440'unarchive模块
默认src是被控端,dest是主控端
## 用于解压文件,模块包含如下选项:
# src: 则需要指定压缩文件的源路径
# dest: 远程主机上的一个路径,即文件解压的路径
# remote_src: 如果为no, 则文件会从主控端复制到被控端。否则会直接尝试从被控端查找文件。默认为no.
# owner: 解压后文件或目录的属主
# group: 解压后文件或目录的属组
# mode: 解压后文件的权限
# creates: 指定一个文件命令,当该文件存在时,则解压指令不执行
# list_files: 如果为yes,则会列出压缩包里的文件,默认为no
## 示例
ansible node1 -m unarchive -a 'src=/opt/xxx.tar.gz dest=/opt/' # 默认src是被控端,dest是主控端
ansible node1 -m unarchive -a 'src=/opt/xxx.tar.gz dest=/opt/ remote_src=yes' # src和dest都是主控端
ansible node1 -m unarchive -a 'src=/opt/xxx.tar.gz dest=/opt/ remote_src=yes list_files=yes' # 列出压缩文件的内容synchronize模块
push:【默认】从主push到被控端
pull: 从被pull到主控端
## 使用rsync同步文件,其参数如下:
# src: 要复制的文件,目录以/结尾表示不包含目录本身,目录不以/结尾表示包含目录本身
# dest: 目录路径
# archive: 归档,相当于同时开启recursive(递归), links, perms, times, owner, group, -D选项都为yes 默认该项为开启
# compress: 是否开启压缩
# rsync_opts: rsync的选项,选项之间用逗号隔开,例如-a, -v, -z等
# delete: 删除不存在的文件,默认no
# dest_port: 默认目录主机上的端口,默认是22,走ssh协议
# mode: push或Pull模块,push模块的话,一般用于从主控端向被控端上传文件,pull模式用于从被控端上取文件,默认是push.
## 使用示例
ansible node1 -m synchronize -a 'src=/etc dest=/tmp/'
ansible node2 -m synchronize -a 'src=/etc dest=/tmp/ archive=no rsync_opts=-r link=yes'
# push在主控端执行
ansible node1 -m synchronize -a 'archive=yes compress=yes dest=/data/ src=/data/ rsync_opts=-vz mode=push'
等同于 rsync -avz /data/* 192.168.23.131:/data/
# pull在被控端执行
ansible node1 -m synchronize -a 'archive=yes compress=yes dest=/data/ src=/data/ rsync_opts=-vz mode=pull'
等同于 rsync -avz 192.168.40.130:/data/* /data/Ansible Playbook 剧本
概述
## 认识playbook
Ad-Hoc ansible的临时指令,用来执行简单的任务。
Playbook ansible的任务编排,用来执行复杂的任务。
YAML语言
# yaml语言
playbook使用yaml语言编写,大小写敏感;使用缩进表示层级关系;缩进时不允许使用Tab键,只允许使用空格;缩进的空格数目不重要,只要相同层级的元素左侧对其即可;#表示注释,从这个字符一直到行尾。
## YAML数据类型详解
# 1. 纯量(scalars): 单个的,不可再分的值
数据最小的单位,不可以再分割,类似于Python中单个变量。
# 2. 数组: 一组按次序排列的值,又称为序列(sequence)/列表(list)与Python的list数组结构类似,数组元素使用短横线"-"开头。
-jack # 也可以写成一行
-Harry # [Jack,Harry,Sunny]
-Sunny # 对应到python的list写法:['Jack','Harry','Sunny']
# 3. 对象: 键值对的集合,又称为映射(mapping)/哈希(hashes)/字典(dictionary)对象的一组键值对,使用冒号结构表示。类似Python中的字典数据结构。
platformName: Windows
platformVersion: 10
Yaml也允许另外一种写法,将所有键值对写成一个行内对象。
{key1:value1, key2:value2}
注意: 冒号后面一定要有空格! 对应到python字典的写法如下
{'key1': 'value1', 'key2': 'value2'}Ansible-playbook语法格式
# ansible-playbook xxx.yaml 执行
- name: # 剧本的名字(剧本的描述信息)
hosts: node1 # 剧本要在哪些主机上工作
remote_user: root # 连接远程用户(可选)如果不写则使用ansible.cfg中的配置
become: yes # 开启提权(可选)如果不写则使用ansible.cfg中的配置
gather_facts: yes # 收集被管理节点的实时变量(yes开启 no/false禁用)默认开启(可选)
vars: # 定义剧本中变量的段落,可以此定义剧本要使用的变量
username: zhangsan # 定义一个变量名username 值是zhangsan
tasks: # 执行任务的段落,剧本中药执行的任务在此定义
-name: create user # 任务的名字(任务的描述信息)
user: 执行任务的模块
name: "{{username}}" # 模块的参数,引用变量
state: present # 模块的参数,创建用户
# 示例 create user
- name: playbook demon1
hosts: all
vars:
username: zhangsan
tasks:
- name: create user
user:
name: "{{ username }}"
state: absent
expires: -1
- name: create group
group:
name: it
state: present
ignore_errors: True
- name: modify user
user:
name: "{{ username }}"
group: it
append: yesAnsible-playbook常用选项
## 1. 打印详细信息
# -v: 打印任务允许结果
# -vv: 打印任务允许结果以及任务的配置信息
# -vvv: 包含了远程连接的一些信息
# -vvvv: Add extra verbosity options to the connection plug-ins, including the users being userdf in the managed hosts to execute scripts, and what scripts have been executed.
ansible-playbook xxx.yaml -vvvv # v越多信息越多,v数量不限制
## 2. 检验playbook语法
ansible-playbook -syntax-check xxx.yaml # 没有回显就说明没问题,^报错一般是对其问题
## 3. 测试运行playbook
# 通过-C选项可以测试playbook的执行情况,但不会真的执行:
ansible-playbook -C xxx.yaml # Ansible-playbook的结构
## playbook是由一个或多个'play'组成的列表,play的主要功能就是对一组主机应用play中定义好的task。从根本上来讲一个task就是对一个ansible 一个module的调用。而将多个Play按照一定的顺序组织到一个palybook中,我们称之为编排。
## palyboook主要有以下四部分构成:
#1. Target section: 用于定义将要执行playbook的远程主机及远程主机组上的用户,还包括定义通过什么样的方式连接远程主机(默认ssh)
- name: # 剧本的名字(剧本的描述信息)
hosts: node1 # 剧本要在哪些主机上工作
remote_user: root # 连接远程用户(可选)如果不写则使用ansible.cfg中的配置
become: yes # 开启提权(可选)如果不写则使用ansible.cfg中的配置
gather_facts: yes # 收集被管理节点的实时变量(yes开启 no禁用)默认开启(可选)
#2. Variable section: 定义playbook运行时需要使用的变量
vars: # 定义剧本中变量的段落,可以此定义剧本要使用的变量
username: zhangsan # 定义一个变量名username 值是zhangsan。 "{{ zhangsan }}" 调用方式
#3. Task section: 定义将要在远程主机上执行的任务列表。按从上往下顺序执行(每个host为单位),有报错就会停止执行。
tasks: # 执行任务的段落,剧本中药执行的任务在此定义
-name: create user # 任务的名字(任务的描述信息)
user: 执行任务的模块
name: "{{username}}" # 模块的参数,引用变量
state: present # 模块的参数,创建用户
#4. Handler section: 定义task执行完成以后需要调用的任务。这是一组特定的任务,一般情况下不会执行,当监听的任务状态对被控主机造成改变时就会触发hardler。(因此在ansible中奖handler段落中的任务称为处理程序)【单个hosts的tak错误处理】
1、根据任务使用的模块不同,解决方法不同
如果是shell模块, shell: ls /opt/test.txt || /bin/true # 使用 || /bin/true让返回值为true。 echo $0返回值0
如果是非shell模块, 使用ignore_errors: true忽略错误
- name: create group
group:
name: it
state: present
ignore_errors: TrueAnsible-playbook Handler
## 假设我们有一套部署在多台服务器上的web应用,每当更新了代码部署到服务器上后,需要重启应用程序才能使新代码生效。但是,如果每次手动去在服务器上重启应用程序的话,会非常耗时且容易出错。这时候,可以使用Ansible Handler来自动化重启应用程序的过程。
## 使用Ansible Handle可以实现部署后自动重启应用程序服务的过程,避免手动操作繁琐、易出错的问题,提高了部署效率和系统可靠性。
# 在Ansbile Playbook中,Handler事实上也是个task,只不过这个task默认并不执行,只有在被触发时才执行。
# handler通过notify来监视某个或者某几个task,一旦task执行结果发生变化,则触发handler,执行相应操作。
# handler会在所有的play都执行完毕之后才会执行,这样可以避免当handler监视的多个task执行结果都发生了变化之后而导致handler的重复执行(handler只需要在最后执行一次即可。)
## handler用来监听ansible中的任务状态,当一个任务的状态是changed的时候就会触发handler,通过notify监听任务,通过handlers中同名任务的name来触发相应的处理程序。
- name: configure apache
hosts: node1
task:
- name: install apache
yum:
name: httpd
state: present
- name: modify apache conf
copy:
dest: /etc/httpd/conf.d/ansible.conf
content: |
<VirtualHost *:80>
ServerName example.com
DocumentRoot /var/www/html
</VirtualHost>
notify: status_http # copy任务changed成功才调用下面的handler对应的status_http函数
handler:
- name: status_http
systemd:
name: httpd
state: restarted
## [listen: 一个任务触发多个处理程序, handlers名字这时可以自定义]
# listen指令可以让Ansible Handler只在某个特定事件发生时才被执行,当一个任务需要通知许多处理程序时,这种方法非常有用。任务只发送一个通知,而不是通过名称通知每个处理程序。Ansible触发所以监听该通知的处理程序。
- name: configure apache
hosts: node1
task:
- name: shell1
shell: touch /opt/file01
notify: get
handlers:
- name: restart httpd
systemd:
name: httpd
state: restarted
listen: get
- name: enabled httpd
systemd:
name: httpd
enabled: yes
listen: get
## Handler强制处理【如果notify任务发生改变触发handler,但是playbook中断退出了,也来不及执行了】
- name: configure apache
hosts: node1
force_handler: yes # 只要notify被触发,脚本退出也会执行。
task:
- name: shell1
shell: touch /opt/file01
notify: getAnsible变量
## ansible变量
# 格式要求
1. 变量名只能由字母、数字或者下划线;来组成
2. 变量名必须以字母开头
3. ansible的内置关键字不能作为变量 # 尽量不要以ansible开头定义变量名
# 查看变量
debug: 模块来查看变量
msg: 输出字符串内容
var: 输出变量的值
var和msg不可以共用
### 在inventory清单中定义变量
## 内置连接变量
baidu ansible_host=node1 # 定义真正连接的主机, ansible baidu -m ping, 实际操作的是node1,不是baidu
ansible_port # 定义真正连接的端口
ansible_user # 定义真正连接的用户
## 内置提权变量
ansible_become # 相当于ansible_sudo或者ansible_su,允许强制特权升级
ansible_become_user # 通过特权升级到的用户,相当于ansible_sudo_user或者ansible_su_user
ansible_becom_pass # 提升权限时,如果需要密码的话,可以通过该变量指定,相当于ansible_sudo_pass
ansible_sudo_exec # 如果sudo命令不在默认路径,需要指定sudo命令路径
## 内置特定ssh连接
ansible_connection # SSH连接的类型:local, ssh, paramiko, 默认ssh
ansible_ssh_pass # ssh连接时的密码
ansible_ssh_private_key_file # 密钥文件路径,如果不想使用ssh-agent管理密钥文件时可以使用此选项
ansible_ssh_executable # 如果ssh指令不在默认路径当中,可以使用该变量来定义其路径
# 示例
192.168.23.[51:52] ansible_port=2222 ansible_user=zhangsan ansible_becom=yes ansible_become_user=student ansible_becom_pass=redhat ansible_connection=ssh ansible_ssh_pass=redhat ansible_ssh_private_key=
## 自定义变量 vim hsots
# 给单主机定义变量
192.168.23.[51:52] webserver=anache
# 给组定义变量
[groupname1]
node1
[groupname1:vars]
dbname=mysql # 组定义变量
# ad-hoc
ansible all -m debug -a 'msg="{{ webserver }}"'
# playbook
- name: get vars
hosts: all
tasks:
- name: print debug info
debug:
msg: "{{ webserver }}"
## playbook中通过vars关键字定义变量
- name: playbook demon1
hosts: all
vars: # var定义
username: zhangsan
tasks:
- name: create user
user:
name: "{{ username }}"
state: absent
## 通过vars_files关键字引入变量文件
# 创建users.yml文件
bob:
name: bob
uid: 1008
home: /bob
shell: /sbin/nologin
alice:
name: alice
uid: 1009
home: /home/alice
shell: /bin/bash
# 在playbook中引入
- name: playbook demon1
hosts: all
vars_files: # 引入变量文件
- users.yml
tasks:
- name: create user
user:
name: "{{ bob.name }}" # 使用对象的属性值
uid: "{{ bob.uid }}"
home: "{{ bob.home }}"
shell: "{{ bob.shell }}" # 也可以使用 {{ bob['shell'] }} 方式
create_home: yes
## 通过host_vars和group_vars目录定义变量
# 在主机的文件中定义变量,在host_vars目录中使用主机名创建一个同名的文件,例如vim host_vars/node1, yml格式,使用 ":"
webserver: nginx
# 在主机组的文件中定义变量,在group_vars目录中使用主机组名创建一个同名的文件,例如 vim group_vars/group
webserver: nginx
# 主机文件和主机组文件变量冲突了,优先级如下:
主机变量>主机组变量。先读取组变量,后面读取主机变量,最后生效的是主机变量。
## 注册变量【register: 任务执行的结果保持下来作为变量】
# 应用场景1:根据一个任务状态来决定是否执行后续的任务
- name: register variables
host: node1
tasks:
- name: capture output of whoami command
command: whoami
register: login # 将任务的结果复制给login
- name: file name
file:
path: /etc/ssh/sshd_config
state: file
register: get_file # 这个也是注册变量
- debug:
var: login
# 应用场景2:在一台远端的服务器获取一个目录下的列表的文件,然后下载这些文件。例如temp
- name: get vars
hosts: all
tasks:
- shell: ls /tmp
register: get_file # 这个也是注册变量
- debug:
var: get_file.stdout_lines # 查看文件命令
# 应用场景3:在handler执行之前,发现前面一个task发生了changed, 然后执行一个指定的task
# 应用场景4:获取远端服务器的ssh key的内容,构建出known_hosts文件。 /etc/ssh/ssh_host_ecdsa_key.pub 保存到 /root/.ssh/known_hosts下就可以了
## 通过命令行设置变量
ansible all -m debug -a 'var=test' -e '{ test: hello }'
ansible all -m debug -a 'var=test' -e '{ test: hello, rhel: 8.4 }'
## 变量的引用和调试输出
## 补充
在inventory主机清单中使用 "=" 定义变量,因为默认主机清单是ini的格式
在playbook中使用 ":" 键值对定义 yaml对象

ansible_facts事实变量
【python版本很重要】:ansible是使用python写的,尽量使用一样的python版本。不然执行会有差异
解决方法:指定python版本,在ansible.cfg来指定。'filter=ansible_python_version'
## 事实变量: facts变量,facts用来作为收集被控主机信息的一个方式。
# 场景:10台服务器,需要知道主机名,IP地址,内存,CPU,存储。ansible-tower需要安装到某一台机器上,安装节点的主机内存要大于4G,需要收集被管控节点的内存信息。
# facts方法来自于setup模块, 通过facts方法获取被管理节点的信息。
ansible all -m setup # 获取主机的所有facts信息
# 使用filter过滤的key只能是第一层级 ansible开头的, 注册到ansible_facts对象里面的子集,不可以是孙集。
ansible all -m setup -a 'filter=ansible_user_shell' # 只查询要过滤的信息
ansible all -m setup -a 'filter=ansible_hostname' # 主机名: node1
ansible all -m setup -a 'filter=ansible_product_serial' # 序列号
ansible all -m setup -a 'filter=ansible_ens33' # 网卡信息
ansible all -m setup -a 'filter=ansible_all_ipv4_addresses' # IP地址
ansible all -m setup -a 'filter=ansible_memtotal_mb' # 显示系统总内存: 6645
ansible all -m setup -a 'filter=ansible_python_version' # Python版本: 2.7.18 【重要,ansible是使用python写的】
ansible all -m setup -a 'filter=ansible_distribution' # 显示是什么系统: Kylin Linux Advanced Server
ansible all -m setup -a 'filter=ansible_distribution_major_version' # 显示是什么系统: v10
ansible all -m setup -a 'filter=ansible_devices' # 显示磁盘设备信息
ansible all -m setup -a 'filter=ansible_lvm' # 显示lvm相关信息
ansible all -m setup -a 'filter=ansible_kernel' # 内核版本: 4.19.90-89.31.v2401.ky10.x86_64
ansible all -m setup -a 'filter=ansible_fqdn' # 显示主机fqdn: node1
# 导出文件
ansible all -m setup --tree /opt # 将主机的facts信息保存到该目录下,使用主机名作为文件名。作用 > /opt/xxx.facts重定向一样
ansible all -m setup --tree > /opt/xxx.facts
## 时间跟踪执行时间
time ansible-playbook xxx.yml # 默认隐藏文件就是facts收集被控端的信息,导致时间很慢。
- name: register variables
host: node1
gather_facts: false # no/false都可以,关闭facts,时间会很快。
tasks:
## 自定义facts变量
# 每一个主机都可以有自己独特的facts变量,管理员可以预先给不同的主机设置facts变量。
# 设置方法:
1. 在主机上创建一个 /etc/ansible/facts.d的目录,然后将自定义的变量文件推送到该目录下,以.fact结尾。
2. 自定义的文件支持ini和jason格式,例如 vim webserver.fact的变量文件(ini格式)
[apache]
name=httpd
version=2.4
service=httpd.service
3. 推送fact文件到facts.d目录
- name: set facts for node1
hosts: node1
tasks:
- name: create dir for ansible
file:
path: /etc/ansible/facts.d
state: directory
- name: copy file
copy:
src: webserver.fact
dest: /etc/ansible/facts.d/webserver.fact
- name: set facts for node2
hosts: node2
tasks:
- name: create dir for ansible
file:
path: /etc/ansible/facts.d
state: directory
- name: copy file
copy:
src: dbserver.fact
dest: /etc/ansible/facts.d/dbserver.fact
4. 使用自定义的fact变量
ansible node1 -m setup -a 'filer=ansible_local' # ansible_local是自定义的fact变量
## 组合fact变量生成新的变量 "-"
- name: set facts
hosts: node1
tasks:
- name: vars
set_fact:
HOSTNAME: "{{ ansible_product_serial }}-{{ ansible_ens33 }}"
test: "test" # 纯文本也支持
- deubg:
var: HOSTNAME
jinjia2变量模版文件
# 创建一个 httpd.conf.j2 模版文件(xxx.j2,不一定以.j2结尾),模版文件可以包含变量
Listen {{ ansible_ens3.ipv4.address }}:80
# 在playbook.yml文件中的task中,将copy更换成template
- name: configure httpd
template: # 要使用该模块才可以
src: httpd.conf.j2
dest: /etc/httpd/conf/httpd.conf
## Ad-hoc
ansible all -m template -a 'src=xxxx.j2 dest=/opt/ip.txt' # 没有收集事实变量,一般不在Ad-hoc使用,除非使用-e指定变量lookup/query查找插件
### lookup通常获取静态的数据,数据类型不一样,lookup通常返回的是列表。只能获取主控端的文件和变量
# 从外部的数据源获取变量,从文件获取变量。将主控端的文件内容作为变量的值。
### 查询方法类型
ansible-doc -t lookup -l # 查看支持的方法
ansible-doc -t lookup url # 查看 url方法的使用方法
# 使用Lookup的方法格式
lookup('方法','内容')
## 应用场景: 批量给所有的主机下发ssh的公钥lab_ras.pub,放在/opt/pubkey
# vim pushkey.yml
- name: create key file
hosts: all
vars:
key_file: "{{ lookup('file', '/root/.ssh/id_rsa.pub') }}"
tasks:
- name: create pubkey
copy:
content: "{{ key_file }}"
dest: /home/username/.ssh/authorized_keys
### query通常获取动态内容,数据类型不一样,query通常返回的是字典 file【ansible2.5以后引入】
- name: create key file
hosts: all
vars:
key_file: "{{ query('file', '/root/.ssh/id_rsa.pub') }}"
tasks:
- debug:
msg: "{{ key_file }}"
### 可以将内容进行哈希加密 password
- name: create key file
hosts: all
vars:
key_file: "{{ lookup( 'password', 'redhat' ) }}"
tasks:
- debug:
msg: "{{ key_file }}"
### 可以将一条命令的执行结果作为变量的值 pipe执行命令
- name: create key file
hosts: all
vars:
key_file: "{{ lookup( 'pipe', 'ls /etc/ansible' ) }}"
tasks:
- debug:
msg: "{{ key_file }}"
### 输出环境变量
- name: create key file
hosts: all
vars:
key_file: "{{ lookup( 'env', 'PATH' ) }}"
tasks:
- debug:
msg: "{{ key_file }}"
### 将链接的内容作为变量的值
- name: create key file
hosts: all
vars:
key_file: "{{ lookup( 'url', 'https://baidu.com/index.html' ) }}"
tasks:
- debug:
msg: "{{ key_file }}"
Ansible魔法Magic变量
所谓的魔法变量指的就是ansible的内置变量,只是这些变量已经定义好特定用途。
## 常用的魔法变量
# 1. ansible_version # 获取ansible版本
# 2. hostvars # [重要]获取指定主机的facts信息。 hostvars['192.168.23.51'].ansible_hostname (:node1)
- name: get vars
hosts: all
tasks:
- debug:
msg: "{{ hostvars['192.168.23.51'].ansible_hostname }}"
# 3. inventory_hostname # 获取正在允许任务的主机名 (:node1/node2)
- name: get vars
hosts: all
tasks:
- debug:
msg: "{{ hostvars[inventory_hostname].ansible_hostname }}" # 主机名, 如果[]里面的内容是变量就不用单引号
msg: "{{ hostvars[inventory_hostname].ansible_ens33.ipv4.address }}" # IP
# 4. groups # 获取主机清单中所有主机[循环常用]
msg: "{{ groups }}" # 获取清单中所有主机组的信息
msg: "{{ groups.all }}" # 获取所有主机的信息,不包含主机组
msg: "{{ groups.groupname }}" # 获取指定主机组信息
when: group_names==diy_groupname # 如果是这diy_groupname组内才执行
when: "'diy_groupname' in group_names"
# 5. play_hosts # 运行的play的主机
# 6. inventory_dir # 清单所在目录;
# 7. inventory_file # 清单文件的路径Ansible变量优先级
# 定义变量的方法
主机清单
主机和主机组的文件
playbook的vars变量
vars_files
命令行
任务注册为变量
set_fact生成变量
内置的facts变量
roles定义变量
...
# 变量的优先级,从高到低【变量名相同的覆盖】
1. 命令行 # -e / --extra key=value
2. playbook # playbook.yml
3. group_vars / host_vars # 可以覆盖 inventory
4. inventory # hosts,无法替换内置变量ansible_name等, 可以覆盖 roles
5. rules #
6. facts #
7. 内置变量: 操作系统版本、系统磁盘信息
变量名相同,高优先级的变量覆盖低优先级的变量
变量名相同,主机变量覆盖主机组的变量
变量名相同,主机组的变量覆盖嵌套组的变量Playbook条件语句
概述
# 在有的时候的结果依赖于变量,fact或者是前一个任务的执行结果,或者基于上一个task执行返回的结果而决定如何执行后续的task,这个时候就需要用到条件判断。
# 条件语句在Ansible的使用场景
1. 在目标主机上定义一个硬限制,比如目标主机的最小内存必须达到多少,才能执行该task
2. 捕获一个命令的输出,根据命令输出结果的不同以触发不同的task
3. 根据不同目标中间件的facts,以定义不同的task
4. 根据目标机器的cpu的大小,以调优相关应用性能
5. 用于判断某个服务的配置文件是否发生变更,以确定是否需要重启服务
when条件语句的用法
## when基本用法
# 在ansible中,使用条件判断的关键字就是when。如在安装包的时候,需要指定主机的操作系统类型,或者是当操作系统的硬盘满了之后,需要清空文件等,可以使用when语句来判断。当表达式的结果返回的时false,便会跳过本次任务。
# 基本用法示例-【在node1上输出hello ansible, 但是剧本中要包含所有主机】
- name: when demo1
hosts: all
tasks:
- debug:
msg: "hello ansible"
when: inventory_hostname == "192.168.23.51" # 这个是hosts里面的主机标识
when: ansible_hostname == "node1" # 作用相识,这个是主机名
比较运算符
# 在ansible中,还支持如下比较运算符
1. ==: 比较两个对象是否相等,相等则返回真。可用于比较字符串和数字
2. !=: 比较另两个对象是否不等,不等则为真
3. >: 比较两个对象的大小,左边的值大于右边的值,则为真
4. <: 比较两个对象的大小,右边的值大于左边的值,则为真
5. >=: 比较两个对象的大小, 左边的值大于等于右边的值,则为真
6. <=: 比较两个对象的大小,右边的值大于等于左边的值,则为真
# 示例, {{ ansible_hostname | type_debug }} 输出变量的类型
when: ansible_machine == "x86_64"
when: ansible_memtotal_mb <= 512逻辑运算符
# 在Ansible中,除了比较运算符,还支持逻辑运算符
1. and: 逻辑与,当左边和右边两个表达式同时为真,则返回真
2. or: 逻辑或,当左边和右边两个表达式任意一个为真,则返回真
3. not: 逻辑否/非, 对表达式取反
4. (): 当一组表达式组合在一起,形成一个更大的表达式,组合内的所有表达式都是逻辑与的关系。
# 示例
when: ansible_machine == "X86_64" and ansible_hostname == "node1"条件判断
# shell模块任务执行结果注册成为变量,然后判断rc的值是否为零,如果值为零则命令执行成功
- shell: ls /opt
register: get_file
- debug:
msg: "hello anable"
when: get_file.rc==0
# 一般在非shell的模块中是没有rc的值,所有对非shell的模块可以判断 failed 或者是 changed
when: get_file.failed != "true"
# 判断路径是否存在
vars:
filepath: /opt
tasks:
- debug:
msg: "hello ansible"
when: filepath is exists # 判断路径是否存在
when: "'/opt/aaa' is exists" # 这个案例一般情况不推荐,使用变量来判断
# 判断变量是否定义
defined # 变量已经定义
undefined # 变量未定义
none # 变量是空值 key:
when: filepath is defined
when: filepath is undefined
## 判断任务的执行结果
# ok: 目标状态与期望值一致,没有发生变更
# change或changed: 目标发生变更,与期望值一样
# sucess或succeeded: 目标状态与期望值一致,或者任务执行成功
# failure或failed: 任务执行失败
# skip或skipped: 任务被跳过
when: get_file is changed
## 判断路径【判断主控端的】
# file: 判断指定路径是否为一个文件,是则为真
# directory: 判断指定路径是否为一个目录,是则为真
# link: 判断指定路径是否为一个软链接,是则为真
# mount: 判断指定路径是否为一个挂载点,是则为真
# exists: 判断指定路径是否存在,是则为真
when:
## 判断字符串
# lower: 判断字符串的所有字母是否都是小写,是则为真
# upper: 判断字符串中所有字母是否都是大写,是则为真
when: str is lower
## 判断数字
# even: 判断数值是否为偶数,是则为真
# odd: 判断数值是否为奇数,是则为真
# divsibleby(num): 判断是否可以整除指定的数值,是则为真
when: number is even
## 比较指定版本
# 格式 version("版本号", "比较运算符")
# 比较运算符
大于: >,gt
大于等于: >=,ge
小于: <,lt
小于等于: <=,le
等于: =,==,eq
不等于: !=,<>,ne
when: ansible_version.full is version("2.8", "eq")
## 判断集合
# 1. subset判断一个list是不是另一个list的子集
when: a is subset(b)
# 2. superset判断一个list是不是另一个list的子集
when: b is superset(a)
# 3. in 判断一个字符串是否存在于另一个字符串中,也可用于判断某个特定的值是否存在于列表中
supported_distros:
- RedHat
- CentSO
when: ansible_distribution in supported_distros
# 4. string 判断对象是否为一个字符串,是则为真
when: var1 is string
# 5. number 判断对象是否为一个数字,是则为真
when: var3 is numberblock, resuce和always
## 条件判断与block【多任务同时使用一个条件来判断】
# 我们在前面使用when做条件判断时,如果条件成立则执行对于的任务。但这就面临一个问题,当我们要使用同一个条件判断执行多个任务的时候,就意味着我们要在某一个任务下面都写一下when语句,而且判断条件完全一样。这种方法不仅麻烦而且显得low。Ansible提供了一种更好的方法来解决问题,即block。
# 在ansible中,使用block将多个任务进行组合,当作一个整体。我们可以对这一个整体做条件判断,当条件成立时,则执行任务中的所有任务。
- name: when demon
hosts: all
tasks:
- name: block demon
block:
- yum:
name: httpd
state: present
- yum:
name: mariadb
state: present
- yum:
name: php
state: present
when: ansible_os_family == 'RedHat'
## rescue【block报错后执行rescue,有点像异常捕获】
# block除了能和when一起使用之外,还能作错误处理。这个时候就需要用到rescure关键字。
- host: test
tasks:
- block:
- shell: 'ls /testdir'
rescure:
- debug:
msg: '/testdir is not exists'
## always 【无论如何都要执行】
- host: test
tasks:
- block:
- shell: 'ls /testdir'
rescure: # block执行失败才会执行
- debug:
msg: '/testdir is not exists'
always: # 都会执行
- deubg:
msg: "hello always"
## 考试题:分区/dev/vda 800的分区,如果800M分不出来,空间不够则分400M;不管分的是400M还是800M,最终都格式化为xfs的文件系统并挂载给/mnt
block 800M
rescure 400M
always xfs mount
条件判断与错误处理
## fail 【条件不成立时,结束playbook的执行】
# 在shell中,可能会有这样的需求: 当脚本执行至某个阶段时,需要对某个条件进行判断,如果条件成立,则立即终止脚本的运行。在shell中,可能直接调用"exit"即可执行退出。事实上,在playbook中也有类似的模块可以做这个事情,即fail模块。
# fail模块用于终止当前playbook的执行,通常与条件语句组合使用,当满足条件时,终止当前play的运行。选项只有一个: msg: 终止前打印信息。
# 示例
- name: fail demon
hosts: all
tasks:
- debug:
msg: "msg1"
- debug:
msg: "msg2"
- fail:
msg: "exit playbook"
when: ansible_os_family=="RedHat"
- debug:
msg: "msg3"
- debug:
msg: "msg4"
## failed_when 对任务进行判断,条件成立时直接结束运行
# 事实上,当fail和when组合使用的时候,还有一个更简单的写法,即failed_when,当满足某个条件时,ansible主动触发失败。
# ansible一旦执行返回失败,后续操作就会中止,所以failed_when通常可以用于满足某种条件时主动中止playbook运行的一种方式。
- name: failed_when demon
hosts: all
tasks:
- debug:
msg: "msg1"
- debug:
msg: "msg2"
failed_when: ansible_os_family=="RedHat" # 如果是真,就不会执行msg2
- debug:
msg: "msg3"
- debug:
msg: "msg4"
Playbook循环语句
概述
# 我们在编写playbook的时候,不可避免的要执行一些重复操作,比如执行安装软件包,批量创建用户,操作某个目录下的所有文件等。正如我们所说,ansible是一门简单的自动化语言,所以流程控制、循环语句这些编程语言的基本元素它通用都具备。
# 在Ansible2.5以前,playbook通过不同的循环语句实现不同的循环,这些语句使用with_作为前缀。这些语法目前仍然兼容,但在未来的某个时间点,会逐步废弃。
# 基本循环-with的前缀语句。ansible2.5开始使用loop来进行循环。
列表方法: with_items
字典方法: with_dict
基本循环列表 with_items
## 【列表】应用场景 with_items
# 场景一:一次性需要创建多个组或者安装多个软件包
# 在主机上创建多个组: alice_group, bob_group, natasha_group
- name: with demon
hosts: all
vars:
user_groups:
- alice_group
- bob_group
- natasha_group
tasks:
- name: create groups
group:
name: "{{ item }}"
state: present
with_items: "{{ user_groups }}"
- name: install packages
yum:
name: "{{ item }}" # 引用变量
state: present
with_items: # 自己定义列表,也可以直接写成一行["item1", "item2", "item3"]
- vsftpd
- dhcp-server
- cifs-utils
# 场景二:创建用户并指定用户的信息
- name: create user
hosts: all
vars:
users:
- name: bob
group: bob_group
uid: 1008
- name: alice
group: alice_group
uid: 1009
tasks:
- user:
name: "{{ item.name }}"
uid: "{{ item.uid }}"
group: "{{ item.group }}"
state: present
with_items: "{{ users }}"基本循环字典with_dict
## 【字典】应用场景 with_dict
# 场景一:循环的对象是一个嵌套的字典,比如用户的信息
- name: dict demon
hosts: all
vars:
users:
alice:
name: Alice Appleworth
telephone: 123-456-7890
bob:
name: Bob Bananarama
telephone: 987-654-3210
tasks:
- debug:
msg: "{{ item.key }} is {{ item.value.name }} {{ item.value.telephone }}"
with_dict: "{{ users }}"
循环语句loop
## loop来代替 with_X风格的关键字
# 在ansible 2.5及以前的版本当中,所有的循环都是使用with_X风格。但是从2.6版本开始,官方开始推荐使用loop关键字来代替with_X。
# "|"过滤器在ansible中专门用来处理数据, 例如hash_password加密数据
## 示例
# 1. 启动httpd和postfix服务
- hosts: all
task:
- name: postfix and httpd are running
systemd:
name: "{{ item }}"
state: strated
loop:
- postfix
- httpd
# 2. 示例过滤器 "|",将 users的内容或者值交给 dict2items过滤器来进行处理
- name: dict demon
hosts: all
vars:
users:
alice:
name: Alice Appleworth
telephone: 123-456-7890
bob:
name: Bob Bananarama
telephone: 987-654-3210
tasks:
- debug:
msg: "{{ item.key }} is {{ item.value.name }} {{ item.value.telephone }}"
loop: "{{ users|dict2items }}" # "|" 是过滤器Ansible Roles角色
概述
# 在Ansible中,role是将playbook分割为多个文件的主要机制。它大大简化了复杂playbook的编写,同时还使得它们非常易于复用。
# 创建role的步骤如下:
1. 创建以roles命名的目录
2. 在roles目录中分别创建角色名称命名的目录,如webservers等
3. 在每个角色命名的目录中分别创建files, handlers, meta, tasks, templates和vars目录,用不到的目录可以创建为空的目录,也可以不创建。
4. 在playbook文件中,调用各角色。
## role的基本构成
# files: 用于存放一些非模版文件,如https证书等
# tempaltes: 用于存放角色相关的jinja2模版文件,当使用角色相关的模版时,如未明确指定模版路径,则默认使用此目录中的模版
# tasks: 角色所要执行的所有任务文件都存放于此,包含一个主文件main.yml,可以在主文件中通过include的方式引入其他任务文件
# handler: 用于定义角色中需要调用的handlers,包含一个主配置文件main.yml,可以通过include引入其他的handler文件
# vars: 用于定义此角色用到的变量,包含一个主文件的mail.yml
# meta: 用于存储此角色的元数据信息,这些元数据用于描述角色的相关属性,包含作者,角色的主要作用,角色的依赖关系等。默认这些信息回写入到当前目录下的main.yml文件中。
# defaults:除了vars目录,defaults目录也用于定义此角色用到的变量,与vars不同的是,defaults中定义的变量的优先级最低。Ansible roles角色管理
# 创建角色
cd roles # 进入到角色目录
ansible-galaxy init apache # 创建apache角色
cd apache # 进入角色的目录
# 引用角色
- name: use apache role
host: all
roles:
- role: apache
roles task
# include_task使用。当任务较多时,可以将任务分开写,通过include_tasks引入
vim roles/tasks/main.yml
- include_tasks:
file: xxxtask.yml
- include_tasks:
file: xxxtask2.yml
# pre_tasks和post_tasks。如果在执行一个role时,需要在其前或者其后依然要执行某些任务,我们可以使用pre_tasks及post_tasks来声明。pre_tasks是在role之前执行,而post_tasks则在role之后执行。
- name: deploy webserver
hosts: all
vars_files:
- secrets.yml
pre_tasks:
- name: debug pre tasks
debug:
msg: "this is a pre tasks"
roles:
- role: apache
post_tasks:
- name: print something
shell: echo "The roles have been updated!"
Roles依赖
# role在执行需要依赖另一个role,可以在roles的meta目录中的main.yml中定义role的依赖关系。
# 示例1, roles/website/meta/main.yml
dependencies:
- role: apache
vars:
apache_port: 80
- role: mysql
vars:
dbname: testdb
# 示例2,, roles/website/meta/main.yml
dependencies:
- {role: ntp, ntp_server=ntp.aliyun.com}
- {role: apache}
- {role: mysql}
role集合2.9以上
# Ansible集合是一种打包盒发布Ansible内容的机制。它可以包含角色、模块、插件、剧本等多个组件,并提供了版本控制和分发控制。集合将相关的功能和资源组织在一起,使其易于管理和共享。通过使用集合,您可以扩展Ansible的功能,引入更多的角色和模块。
# 命名空间是指创建集合的组织、开发者、或者任何其他实体的标识符。通过在集合名称中添加命名空间,可以确保集合名称的唯一性,并且不同的组织或开发者可以使用相同的集合名称而不会产生冲突
# 创建集合
ansible-galaxy collection init 命名空间.集合名 # 创建一个集合【需要在ansible2.9及以上版本】
Ansible的集合需要命名空间是为了维护和组织集合的结构,并避免名称冲突
Ansible Galaxy
# 1. 通过ansible-galaxy初始化的roles目录结构,方法如下:
ansible-galaxy init my_new_role
# 2. 搜索role
ansible-galaxy search myrole
# 3. 安装下载好的的roles:
ansible-galaxy install myrole -p /tmp
# 4. 列出已经安装的roles:
ansible-galaxy list
# 5. 查看已经安装的roles信息
ansible-galaxy info myrole
# 6. 协助roles:
ansible-galaxy remove myrole
# 下载官网: https://galaxy.ansible.comAnsible Vault配置加密
## 概述
# 在使用ansible的过程中,不可避免的会存储一些敏感信息信息,比如在变量文件中存储账号密码信息等。
# ansible通过ansible-vault命令行工具来提供铭感文件的加密和解密
# ansible-vault可以创建、加密、解密和查看文件。其可以加密任何ansible使用的文件,包括inventory文件,playbook调用的变量文件第
## 常用操作
# 1. 创建加密文件
ansible-vault create file
# 2. 编辑加密文件
ansible-vault edit file
# 3. 重置密码
ansible-vault rekey file
# 4. 加密已有文件
ansible-vault encrypt file
# 5. 解密文件
ansible-vault decrypt file
# 6. 查看文件
ansible-vault view file
## 示例
# 示例1: 为一个用户alice_test创建以下用户信息,用户名:alice_test, uid为1090密码redhat,用户的信息需要加密后保存到文件userinfo.yml,使用playbook create_alice.yml根据userinfo.yml的信息创建用户
vim userinfo.yml # 编写数据文件
users:
name: alice_test
uid: 1090
passwd: redhat
ansible-vault encrypt userinfo.yml # 加密文件
vim create_alice.yml
- name: create user alice
hosts: all
vars_files:
- userinfo.yml
tasks:
- user:
name: "{{ users.name }}"
uid: "{{ users.uid }}"
passwd: "{{ users.passwd|password_hash('sha512') }}"
state: present
ansible-playbook create_alice.yml --ask-vault-pass # 输入解密密码执行
ansible-playbook create_alice.yml --vault-password-file pass.txt # 指定密码文件,密码写到这个文件里面RHCA分界线
Ansible动态清单
# Ansible记录被管理对象的文件被其称为主机清单,默认ansible使用ini格式的文本文件来记录主机信息。
# Ansible2.4开始支持使用不同的插件获取主机清单
# 根据清单的类型不同将清单分为 动态主机清单 和 静态主机清单
1. 静态主机清单: 指将主机列表写在一个文件中,通常是一个INI风格的文本文件,其中包含主机名,IP地址、变量等信息。这个文件需要手动维护,并且是固定不变的。Ansible将根据静态主机清单来管理主机。
2. 动态主机清单:使用插件外部数据源动态生成主机列表。这个数据源可以是虚拟化平台、云提供商或配置管理数据库等,例如AWS EC2实例、VMware虚拟机或DNS解析等。与静态主机清单不同,动态主机清单可以随时更新,并根据实际情况自动添加或删除主机。修改inventory插件
enable_plugins=支持的插件(在ansible.cfg)
# host_list: Ansible支持多种主机清单,其中之一就是hosts_list。他是Ansible的默认主机清单,只用纯文本格式,每一行主机/IP地址
# script: 值得是在Ansible主机清单中通过执行脚本来动态生成主机列表。这需要用户编写自定义脚本来生成主机清单【给执行权限+X】
script支持py/sh等脚本格式,但是所有的脚步必须支持--list(all)和--host(1)这两个参数,且脚本输出的主机清单的格式要为json.
https://docs.ansible.com/ansible/latest/plugins/inventory.html
https://github.com/ansible-community/contrib-scripts/tree/main/inventory # 插件脚本
查看ansible当前支持的所有插件 ansible-doc -t inventory -l
ansible-doc -t inventory online
ansible-inventory xxx.py/.sh --list # 测试脚本
/usr/lib/python3.6/site-packages/ansible/plugins/inventory
# auto: 指的是Ansible动态清单插件,它允许您从外部数据源(如EC2/GCE/WMare等)获取主机清单,可以动态生成并时刻更新。
# yaml: 指的是一种主机清单格式,使用yaml文件格式存储主机清单,与INI格式类似,YAML也支持将主机分组,易于阅读和管理
# ini: 指的是一种主机清单格式,使用INI文件格式存储主机清单。主机可以进行分组,并按照组分别执行任务。
# toml: 指的是一种主机清单格式,TOML文件具有易于编写和阅读的语法,与YAML和INI类似,支持主机分组。
如果使用主机清单时不指定插件ansible根据enable_plugins中的插件顺序依次选择合适的插件
## 案例(华为云)
1. wget https://raw.githubusercontent.com/huaweicloud/huaweicloud-ansible-modules/master/contrib/inventory/requirements-inventory.txt
2. pip3 install -r requirements-inventory.txt -i https://pypi.tsinghua.edu.cn/simple
定义yaml主机清单
## Yaml定义主机清单
yaml在版本管理系统中,可以用来多人协作,并且在版本管理系统中,会记录前后的变化;yaml可以让清单更加层次化,架构更加清晰;一般在大型项目中会使用yaml来定义主机清单,定义静态主机清单。
# yaml定义的规则
1. 每一个主机都必须以冒号结尾(:)
2. 每一个主机都必须属于一个主机组
# xxx.yaml
all:
children:
ungrouped: # 定义单个主机
hosts:
node1:
node2:
web: nginx # 定义单主机变量web
dbbase: mysql # 定义单主机变量dbbase
node3:
webserver: # 定义主机组,和ungrouped对齐
hosts:
node4:
node5:
vars: # 定义主机组变量
rhel: 8.4
dbserver:
hosts:
node9:
childen: # 定义嵌套组
webserver:
vars:
dbname: mysql # 定义嵌套组变量
webserver2: # 定义嵌套组内的主机组 【优化】
hosts:
node6:
node7:
vars: # 定义主机组变量
rhel2: 8.4
## 将ini转换成yaml格式
# ansible-inventory进行格式转换时不会验证主机的真实性,也就是无论清单中的主机是否真实存在,只进行Ini向yaml文件转化
# --yaml指定转为yaml, -i ini格式的清单文件, --list以yaml格式列出,--output输出到新的文件
ansible-inventory --yaml -i hosts --list --output hosts.yamlAnsible提权
在工作中并非每一次操作都需要以root身份来执行;在某一些场景中,可能需要短暂使用root来允许任务,比如配置防火墙、配置selinux、配置网络等系统管理员操作时需要使用root,因此ansible可以在指定的任务或者是主机上或者是角色上来进行提权。
# 全局提权配置: /etc/ansible/ansible.cfg中的提权对所有的主机和playbook生效,如果在配置中开启了提权,则ansible每一次执行任务或者是执行剧本都会以提权的用户来进行。
# Ansible默认以普通用户权限执行任务,这是处于安全性考虑,以防止误操作或滥用管理员权限。然而,在某些情况下,执行特权任务或需要对系统进行修改的操作时,需要提权。
# 提权的位置:playbook, roles, block, task, hosts
# 提权配置: ansible.cfg中privilege_escalation将become: True默认对所有执行的剧本进行提权。
# 提权方式(sudo, su, pbrun, dzdo等)
即使ansible.cfg配置文件中关闭了提权,命令行开启-b选项后提权依然生效。
## 在playbook上提权
- hosts: node1
become: yes
become_method: sudo
become_user: root # ansible-playbook xxx.yml -K # 大K输入提权密码执行
tasks:
- shell: id -un
register: get_status
- debug:
msg: "{{ get_status }}"
## 在tasks中对单个任务提权
- hosts: node1
tasks:
- shell: id -un
register: get_status
- debug:
msg: "{{ get_status }}"
become: yes # 对下面的debug模块提权,ansible-playbook xxx.yml -K # 大K输入提权密码执行
become_method: sudo
become_user: root
- debug:
msg: "{{ get_status }}" # root
## 在roles中进行提权
roles:
- role: role_name
become: true # 对单个role提权
become_method: sudo # 提权方式su就输入root的密码,sudo 就输入当前账号的密码。
become_user: root
## 在block中进行提权
- block:
- shell: id -un
register: get_status
- debug:
msg: "{{ get_status.stdout }}"
become: true
become_method: sudo
become_user: root
## 在hosts.yaml里面开启提权
all:
children:
ungrouped: # 定义单个主机
hosts:
node1:
ansible_become: true
ansible_become_method: sudo
ansible_become_user: root
ansible_become_pass: root_passwd # 这里可以指定提权的密码
Playbook执行顺序
# 一般情况下,只存在task,是从上到下执行的。没有roles/pre_task/post_task和handler情况下
# pre_tasks -> pre_tasks_handler -> roles -> tasks -> roles_handler -> tasks_handler -> post_tasks -> post_tasks_handler # 执行顺序从左到右
# ansible中主机的执行顺序:
ansible默认根据清单文件中定义的主机顺序来依次执行主机,通常默认开启并发,可以在ansible.cfg的forks设置为1,表示ansible不并发
# Ansible根据playboo的hosts带来确定要在哪些主机上执行任务。默认情况下,Ansible2.4及以后版本会按照主机在清单中的顺序依次在主机上执行任务。
# 通过playbook的order控制任务执行的主机顺序。
# Order指令接受以下值
inventory: 清单 order默认值
reverse_inventory: 清单order的倒序
sorted: 主机按字母顺序排序。数字排在字母之前
reverse_sorted: 主机按字母顺序倒序排序
shuffle: 每次运行play时都是随机顺序。
# 使用方法
- hosts: all
order: inventory
tasks:...执行指定tags的任务
# 当使用大型或复制的剧本时,可能只想运行某个play或play中的某个任务
# tags将play或者task进行标记,以便执行或者跳过指定的任务或剧本, 可以同时打多个标签
# 执行剧本:
1. 执行指定的tag的任务 ansible-playbook filename.yml --tags tagname
2. 执行多个tags的任务 ansible-playbook filename.yml --tags tagname1,tagname2
3. 跳过指定tags的任务 ansible-playbook filename.yml --skip-tags tagname
4. 跳过多个tags的任务 ansible-palybook filename.yml --skip-tags tagname1,tagname2
5. 列出剧本中所有存在标签的任务 ansible-playbook filename.yml --list-tags
## 对play进行标记
# 示例
- name: debug1
hosts: node1
tags: hello1 # 对play打tag
tasks:
- debug:
msg: "hello1"
- debug:
msg: "hello2"
tags:
- tag1 # 对单个任务打tag
- tag2
- include_tasks: taskfile.yml
tags: tag3 # 对tasks文件打tag, 文件里面的task也需要打tag
- name: debug2
hosts: node1
roles:
- role: apache
tags:
- roletag1 # 给roles进行标记
tasks:
- debug:
msg: "hello3"
# block也可以打标签。
## 特殊标签
# 定义特殊标签任务
always: 任务打上该标签,不管指定的tag是否匹配,都将执行,除非明确指定 --skip-tags=always选项,跳过always的任务
never: 任务打上该标签,任务总是不执行,除非明确指定 --tags=never才能执行
# 指定特殊标签运行
all 默认执行playbook自带的tag,所有任务都会执行
tagged 执行所有带有tag的任务,never除外
untagged执行所有未打tag的任务,打了always也会被执行,但是always除外
always + never = all
delegate_to委派任务/事实
## 委派任务【控制节点操作的委派节点,在hosts执行的HA需要配置node1/2上的IP地址,可以通过委派控制节点去拿其他节点的信息】
# 在Ansible中,委派任务(Delegated Tasks)允许你将任务委派给远程主机上的不同用户或使用不同身份来运行。通过委派任务,你可以在特定任务级别上更改连接的用户和身份。
# 通常情况下,Ansible会通过SSH连接远程主机,并使用执行Playbook的用户进行操作。但有时你可能需要使用其他用户身份在目标主机上执行特权操作或特定任务
# delegate_to: 将任务委派到指定主机上执行,哪怕这个主机不在清单中。delegate_user等
# 应用场景
1. 跳转主机:当需要在一个主机上执行任务,但又需要依赖于另一个主机上的数据或配置时,可以使用任务委派。通过将任务委派到拥有所需数据或配置的主机,可以在目标主机上获取必要的信息,并将其传递回控制节点。
2. 异构环境:在管理具有不同操作系统、不同配置等异构性的环境时,任务委派非常有用。可以将某些任务委派给特定类型主机进行优化的专门主机,以提高执行效率。
3. 无法直接访问的网络设备:对于无法直接访问的网络设备,比如交换机、路由器和防火墙等,可以使用任务委派来执行特定的网络操作,如配置更改或设备重启。
4. 配置收集:通过将任务委派到已经在网络中部署的代理主机或其他可访问资源,可以收集有关网络中各个主机的配置信息。这样可以快速获取各个设备或主机的配置状态。
5. 特定环境操作:可以使用任务委派进行一些特定环境下的操作,如容器管理、Kubernetes节点配置、云服务API调用等。
#示例
- hosts: 192.168.23.52
tasks:
- name: install pkgs apache
yum:
name: httpd
state: present
delegate_to: 192.168.23.51 # 将这个任务委派给node1执行,其实还是控制节点做
## 事实委派
事实委派就是为了收集委派节点的事实变量,因此在某一些场景中可能需要获取其他主机的facts变量来进行使用。
# 在Ansible中,你可以使用delegate_facts参数来委派收集事实(facts)。delegate_facts参数允许你在任务级别将收集事实的责任委派给不同的主机,并将收集的事实数据返回到控制节点
# delegate_facts: true 开启委派/ false 禁用委派
# 应用场景
1. 局部收集事实:有时候你可能只需要在某个特定的主机上收集事实数据,而不是在所有主机上都执行setup模块。使用事实委派功能,你可以选择性在特定的主机上收集事实数据,并将其传递到控制节点,以便后续任务处理
2. 动态主机:当你使用动态主机清单(Dynamic Inventory)时,可能会遇到需要在每个新加入的主机上收集事实数据的情况。使用事实委派,在动态添加的主机上收集事实数据并将其传递到控制节点,以便后续任务使用。
3. 分布式环境:在分布式环境中,你可能需要在不同的主机群组中执行任务,并将结果传递到控制节点。通过将事实委派给其他主机,你可以在不同的主机群组上执行任务,并将其结果传递到一个集中的位置。facts缓存
只收集一次facts信息,将其缓存下来给到后面的playbook直接调用,ansible支持facts缓存,facts缓存到哪里??
vim ansible.cfg
gathering = implicit # 参数值说明(smart:收集facts并缓存【配置缓存如下】;implicity:收集facts;explicit:不收集facts)
### 设置为smart才需要配置如下缓存配置。
# 缓存时间,单位为妙
fact_caching_timeout=86400 # 1 天
# 存储方式
fact_caching=jsonfile # json, memcached, redis
##[json文件缓存方式] 指定ansible包含fact的json文件位置,如果目录不存在会自动创建,如果是memcached或者redis则为链接方式
fact_caching_connection=/tmp/ansible_fact_cache
##[memcached缓存方式]
gathering = smart
fact_caching_timeout=86400
fact_caching=memcached
fact_caching_connection=127.0.0.1:11211
##[redis缓存方式]
gathering = smart
fact_caching_timeout=86400
fact_caching=redis
fact_caching_connection=127.0.0.1:6379
# 打开缓存,第一次执行速度不变,第二次才快。serial滚动更新
20台主机,升级软件,防止故障,采用滚动更新,【一批一批更新】
## 滚动更新:控制主机的执行数量,来避免故障的批量发生;将清单中的主机按照指定的批次一次去执行任务;当某一批主机执行任务发生错误时,可以立即停止或回滚错误;将其称为滚动更新,更加适合大规模业务场景下的批量升级,部署等操作。
# 默认情况下,Ansible
# 示例
- hosts: all
serial: 2 # 设置每一批2台数量
serial: 25% # 设置每一批25%
serial:
- 1
- 10%
- 30% # 接下的批次按all主机的30%处理完
tasks:
- debug:
msg: "hello ansible"
## 主机失败中断剧本
# 默认情况下,Ansible会尝试让尽可能多的主机来完成剧本。如果某个主机的任务失败,则该任务将被从剧本中删除,但Ansible将继续为其他主机运行剧本中剩余的任务。只有当所有主机都失败时,剧本执行才会停止。
# 使用serial批量执行,一个批次中的所有主机都失败则play终止运行,一个批次中的一些主机失败,不会影响下一个批次的继续运行。
# 通过max_fail_percentage设置最大失败主机比例,即使一个任务中或者一个批次中所有主机没有全部失败也终止整个剧本的运行。(指定批次或者指定任务的主机数达到一定数量则停止剧本的运行)
max_fail_precentage 当该值为0时或者超过该值时,所有有主机失败则立即结束playbook运行。
# 剧本中断
1. 所有的主机在某一个任务全部失败了,则剧本退出,因此此时playbook接着执行没有意义。
2. 人为的中断:可以通过failed_when,或者控制主机失败的数量来中断playbook的执行。
默认情况下:如果一批主机执行某一个任务时,某一台主机或某一些主机发生错误,则此时playbook不会让这批失败的主机继续参加下面的任务;以此来保证更多的主机可以执行任务。
# 示例
- hosts: all
max_fail_precentage: 20% # 在所有的主机中,超过20%的主机报错就退出playbook执行。【要主机上任务失败,主机不可达不算失败】
tasks:...
## 批次&中断
当serial批次中主机失败达到一定比例则停止运行playbook
max_fail_percentage: 20% # all x serial x max_fail_percentagerun_once一次性任务
# 在特定应用场景中,希望某个任务只在某台主机上运行一次,即使它绑定到了多个主机上。例如在一个负载均衡器后面有多台应用服务器,我们希望执行一个数据库迁移,只需要在一个应用服务器上执行操作即可。
# run_once布尔值true或者false开启或者关闭任务只运行一次
run_once默认只会在play中的第一个主机上运行
run_once和serial一起执行,则会在第一批的第一台主机上执行任务
when: inventory_hostname==ansible_paly_hosts[0] # 让任务只在第一批的第一个主机上执行
run_once和delegate_to一起执行,则在指定主机上执行一次任务
vars_prompt交互
# Ansible执行play过程中需要用户输入一些内容;这些数据通常是用户密码或者一些较为保密的内容,且该内容对于不同的用户可能存在不同的值
# Ansible使用vars_prompt来接收用户的输入
hsots: all
vars_prompt:
- name: test_user # 定义变量名
prompt: "请输入用户名" # 定义提示信息
private: yes # 也yes表示输入不可见,no表示输入可见
default: hello # 定义默认值用户直接回车默认输入的内容
task:xxxenvironment环境变量
# 在一些场景中,可能需要在被控端上去执行访问api接口或者是引用某些程序的环境变量,例如在openstack的管理节点上执行命令,则需要openstack的用户环境变量,ansible允许剧本在执行的过程中在被控端上定义环境变量。
# 通过environment在被控端上给指定的任务定义环境变量
# 示例
- hosts: all
- shell: echo $ansible_path > /tmp/ansible.txt # 使用外部脚本也可以调用这里定义的变量
environment:
ansiblek_path: /etc/ansible/ansible.cfgwait_for剧本等待
# 剧本中任务执行的过程中可能需要等待某一些应用或主机的响应然后再继续向下执行任务。比如某一台主机或应用刚刚重启,我们需要等待它上面的某个端口开启,此时就需要将正在运行的任务暂停,指导其状态满足要求。
# ansible中wait_for模块专门用来在剧本执行的过程等待被控端主机达到满足的条件
# wait_for参数
1. connect_timeout: 指定等待期间尝试建立连接的最大时间,单位为秒。如果超过指定的时间仍然无法连接到目标主机,则连接超时错误。
2. timeout: 模块的超时时间,默认为300秒 # 常用
3. delay: 多少秒检查一次,不指定300秒内一直轮询检查到满足条件为止
4. host: 等待主机的地址,默认为127.0.0.1
5. port: 等待主机的端口
6. path: 文件的路径,当文件存在时,下一个任务继续执行,等待文件创建成功
7. state: 等待的状态,当文件或端口达到指定的状态,继续往下执行任务
- 当对象为端口时,started端口开,stoped端口关闭
- 当对象为文件时,present或者stared创建,absent删除
- 当对象为连接时,drained连接未建立。
# 示例1,等待端口被监听
- hosts:all
tasks:
- wait_for:
host: 192.168.1.1
port: 80
state: started
- debug:
msg: "hello ansible"
# 示例2,等待文件被创建
- hosts:all
tasks:
- wait_for:
path: /opt/demon/ansible
delay: 10
state: present
- debug:
msg: "hello ansible"
# 示例3,等待连接断开
- hosts:all
tasks:
- wait_for:
host: 192.168.1.1
port: 22
state: drained # 除了本机连接被控端,其他主机还在连接就等待,等待端口连接后才执行
exclude_hosts: 192.168.1.1 # 忽略特定主机
- debug:
msg: "hello ansible"
lineinfile模块
# 在大多数时候,我们在linux上的操作,就是针对文件的操作,通过配置管理工具对配置文件做统一的配置修改是一个非常酷的功能。lineinfile模块就是针对一个文件中行内容的操作
# 常用参数
1. path: 要修改的文件
2. regexp: 正则表达式匹配要修改的行
3. line: 修改或者插入行的内容
4. insertbefore: 在匹配的行前面插入
5. insertafter: 在匹配的行后面插入
6. backup: 是否备份文件
7. create: 文件不存在则创建文件
8. validate: 验证文件修改的有效性,需要文件自带验证机制
## 实例
# 示例1
- name: modify file
hosts: all
tasks:
- lineinfile:
path: /opt/passwd
regexp: root # 修改找到的第一个匹配的行,从下往上找。regexp: ^root # 以root开头的行
line: redhat # 修改成redhat
# 示例2
- name: modify file
hosts: all
tasks:
- lineinfile:
path: /opt/passwd
insertbefore: ftp # 在ftp行前面插入内容
line: hello # 同一个文件的内容只能修改一次,所有不可以再是redhat了
backup: yes # 备份源文件
# 示例3
- name: create file
hosts: all
tasks:
- lineinfile:
path: /opt/abc.txt
line: hello # 文件内容
create: yes
validate: visudo -cf %s # $s表示path的路径,如果校验不通过,表示文件修改不生效
# 示例4 删除行
- name: create file
hosts: all
tasks:
- lineinfile:
path: /opt/abc.txt
state: absent # 删除行
regexp: root #
blockfile模块
# blcokinfile是对文件进行多行操作,可以插入和追加内容到文件,常用参数与lineinfile类似
# 参数说明:
1. block: 要插入的文本内容
2. market: 指定块标记,"{mark} ANSIBL MANAGED BLOCK"
## 示例
# 示例1
- name: blockinfile demon
hosts: all
tasks:
- blockinfile:
block: | # "|是输入多行内容"
hello ansible
rhca do347
442
path: /opt/abc.txt
maker: ";{mark} do347 test" # mark有自带的标记,加上自己的标记,;可以是文件的注释,类似#
# 示例2 删除标签开始和结束之间的内容
- name: blockinfile demon
hosts: all
tasks:
- blockinfile:
path: /opt/abc.txt
state: absent # 删除标签内的内容
jinja2用法
### jinja2条件语句
# jinja2是一个流行的Python模块引擎,它同样支持条件语句来控制模版中的输出
# 语法格式:条件表达式适用于playbook中的条件语句
## 示例
# 示例1
if 单分支:
{% if 条件表达式 %}
输出满足条件内容
{% endif %}
# 示例2
if 双分支:
{% if 条件表达式 %}
输出满足条件内容
{% else %}
输出不满足条件内容
{% endif %}
# 示例3
if 多分支:
{% if 条件表达式 %}
输出满足条件内容
{% elif 条件表达式2 %}
输出满足条件2的内容
{% else %}
输出不满足条件内容
{% endif %}
## 场景应用
# 场景1
需求:httpd.conf.j2下发到很多的主机上,监听的地址(优先监听bond接口上,如果主机上不存在bond的接口,监听eht0上。如果以上的接口都不存在,则监听默认的IP地址上0.0.0.0:80)
1. vim httpd.conf.j2
{% if ansible_bond0 is defined %} # Listen 80 修改成变量
Listen {{ ansible_bond0.ipv4.address }}:80
{% elif ansible_eth0 is defined }
Listen {{ ansible_eth0.ipv4.address }}:80
{% else %}
Listen 0.0.0.0:80
{% endif %}
### jinja2循环语句
## 格式
{% for 变量名 in items %}
输出每个item
{% endfor %}
## 案例
# 案例1 将主机清单中的主机批量绑定IP和主机名的映射关系
{% for host in groups.all %}
{{hostvas[host].ansible_ens33.ipv4.address}} {{hostvars[host].ansible_fqdn}}
{{hostvars[host].ansible_hostname}}
{% endfor %}
| 过滤器
## default过滤器
# 当指定的变量不存在时,用于设定默认值
- name:get test
hosts: all
tasks:
- file:
path: "{{ path_file|default('/opt/hello.txt') }}"
state: touch
## 字符串操作相关的过滤器
1. upper: 将所有字符串转换成大写
2. lower: 将所有字符串转换成小写
3. capitalize: 将字符串的首字母大写,其他字母小写
4. reverse: 将字符串倒序排序
5. first: 返回字符串的第一个字符
6. last: 返回字符串的最后一个字符
7. trim: 将字符串开头和结尾的空格去掉
8. center(30): 将字符串放在中间,并且字符串两边用空格不齐30位
9. length: 返回字符串的长度,与count等价
10. list: 将字符串转换成列表
11. shuffle: list将字符串转换成列表,但是顺序排序,shuffle同样将字符串转换成列表,但是会随机打乱字符串顺序
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_str.yml
## 数字操作相关的过滤器
1. init: 将对于的值转换为整数
2. float: 将对于的值转换为浮点数
3. abs: 获取绝对值
4. round: 小数点四舍五入
5. random: 从一个给定的范围中获取随机值
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_number.yml
## 列表操作相关的过滤器
1. length: 返回列表长度
2. first: 返回列表的第一个值
3. last: 返回列表的最后一个值
4. min: 返回列表中最小的值
5. max: 返回列表中最大的值
6. sort: 重新排列列表,默认为升序排列,sort(reverse=true)降序
7. sum: 返回纯数字非嵌套列表中所有数字之和
8. flatten: 如果列表中包含列表,则flatten可拉平嵌套的列表,levels参数可以用于指定被拉平的层级
9. join: 将列表中的元素合并为一个字符串
10. random: 从列表中随机返回一个元素
11. shuffle: 将列表中元素随机顺序
12. upper: 将列表中的字符串转换为大写形式
13. lower: 将列表中的字符串转换为小写形式
14. union: 将两个列表合并,如果元素有重复,则只留下一个
15. intersect: 获取两个列表的交卷。
16. difference:获取存在于第一个列表中,但不存在于第二个列表中的元素
17. symmetric_difference: 取出两个列表中各自独立的元素,如果重复则只留一个
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_list.yml
## 注册变量过滤器
将一个任务的执行结果注册保持为变量,通过注册变量过滤器来判断任务是否执行成功,如果任务执行失败,可以通过failed_when主动终止play的执行。
1. failed: 如果注册变量的值是任务failed则返回True
2. changed: 如果注册变量的值是任务changed则返回True
3. success: 如果注册变量的值是任务succeded则返回True
4. skipped: 如果注册变量的值是任务skipped则返回True
ps: 注册变量过滤器已在ansible2.9中进行废弃
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_list.yml
## 应用于文件路径的过滤器
1. basename: 返回文件路径中的文件名部分
2. dirname: 返回文件路径中的目录部分
3. expanduser: 将文件路径中的~替换为用户目录
4. realpath: 处理符号链接后的文件实际路径
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_file.yml
## 加解密过滤器
1. 使用hash过滤器加密内容
2. 使用password_hash过滤器加密内容
3. 使用base64加密和解密内容
例子:https://gitee.com/yflinux/playbook_demo/blob/master/filter_pass.yml
## ipaddr过滤器处理网络地址
# 主控端装包: yum install -y python-netaddr
1. address: 获取IP地址和子网掩码位数
2. host: 获取IP地址和子网掩码为数
3. prefix: 获取网络前缀,前缀是一个用于标记网络地址中网络和主机部分的位数
4. size: 获取子网中可用的IP数量
5. network: 获取子网地址不带掩码
6. netmask: 获取子网掩码
7. broadcast: 获取广播地址
8. subnet: 获取子网地址带掩码
9. ipv4/ipv6: 获取IPv4或ipv46地址
例子: https://gitee.com/yflinux/playbook_demo/blob/master/filter_ipaddr.yml
## url分割过滤器
#urlsplit过滤器用来分割url地址,支持参数如下
1. hostname: 获取url中的域名(主机名)部分
2. netloc: 获取url中的域名和端口,如果有认证用户信息也会返回用户认证信息
3. path: 获取url中网页文件的路径地址
3. port: 获取url的端口
4. scheme: 获取url协议, http或者https
5. query: 查询url后面的字符串部分即以?(问号)开头的部分
例子: https://gitee.com/yflinux/playbook_demo/blob/master/filter_urlspilt.yml
## 查找替换过滤器
1. replace: 替换匹配到的字符串或者子字符串
2. regex_replace: 替换匹配到的字符串或者子字符串,支持正则表达式
3. regex_search: 在字符串中搜索匹配正在表达式的内容,返回第一个匹配的字符串或子字符串。如果找不到则返回空字符串
4. regex_findall: 查找字符串中所有匹配正在表达式的字符串或子字符串。
例子: https://gitee.com/yflinux/playbook_demo/blob/master/filter_replace.yml
## 表达式
1. \w 匹配字母数字及下划线
2. \W 匹配非字母数字及下划线
3. \s 匹配任意空表字符,等价于[\t\n\r\f]
4. \S 匹配任意非空字符
5. \d 匹配任意数字,等价于[0-9]
6. \D 匹配任意非数字
7. \A 匹配字符串开始
8. \Z 匹配字符串结束,如果存在换行,只匹配到换行前的结束字符串。
9. \z 匹配字符串结束
10. \G 匹配最后匹配完成的位置
11. \b 匹配一个单元边界,也及时只单词和空格间的位置,例如, 'er\b'可以匹配'never'中的'er',但不能匹配'verb'中的'er'
12. \B 匹配非单词边界。'er\B'能匹配'verb'中的'er',但不能匹配到'never'中的'er'
13. \n,\t 等匹配一个换行符,匹配一个字表符
14. \1..\9 匹配第n个分组的内容
15. \10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符的表达式
## 字典变量的过滤器
1. combine: 将两个字典合成一个
2. dict2items: 将字典转换为列表
3. items2dict: 将列表转换成字典
4. to_json/to_yaml将变量转换为json或yaml格式
5. to_nice_json/to_nice_yaml将变量转换成易读的json或者yaml格式
6. from_json/from_yaml从json或者yaml读取数据
例子: https://gitee.com/yflinux/playbook_demo/blob/master/filter_dict.yml
## 自定义大写转换过滤器
# 在ansible.cfg中定义过滤器的路径
fileter_plugins=/usr/share/ansible/plugins/filter # 开启自定义过滤器位置
# 编写python代码
def ansible_test(value): #定义一个名为ansible_test的函数,并接受value的值
return value.upper() # 将返回的value输出为大写
class FilterModule(object): # 定义一个名为filterModile的类
def filters(self):
return {'ansible_test': ansible_test}
# 测试过滤器效果
- debug:
msg: "{{ hello ansible | ansible_test }}"Ansible FQA
主控端
没有sshpass包
# 没有sshpass包,需要安装
rpm -ivh ./ansible-2.8-for-rhel-8-x86_64-rpms/Packages/s/sshpass-1.06-3.el8ae.x86_64.rpmSSH connnect error
# vim /etc/ansible/ansible.cfg
[ssh_connection]
ssh_args = -o ControlMaster=auto -o ControlPersist=60s -i /root/.ssh/id_rsa # -i /root/.ssh/id_rsa指定免密登录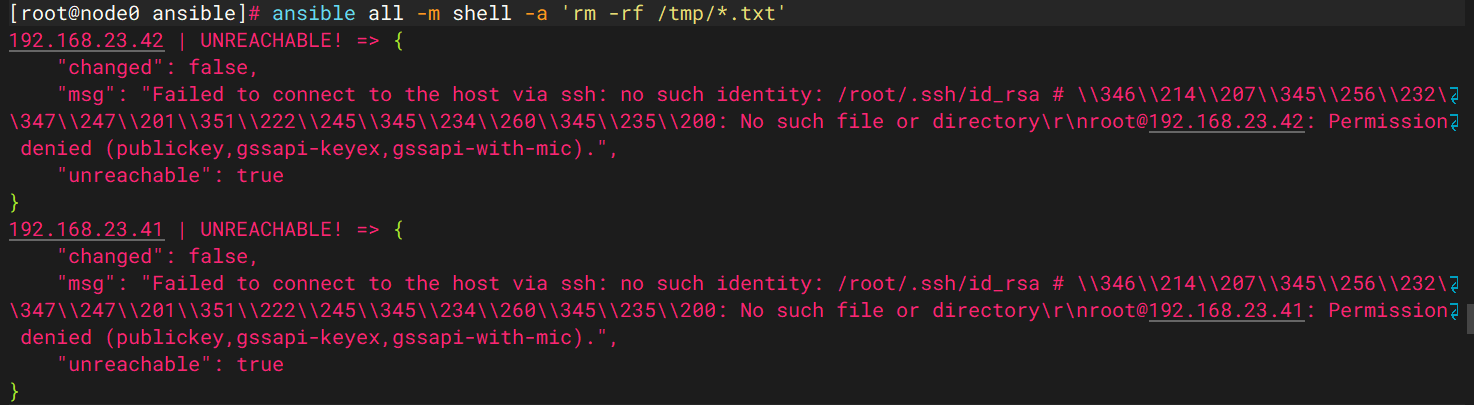
python告警问题
[defaults]
interpreter_python = /usr/bin/python3
被控端
密钥登录
# vim /etc/ssh/sshd_config
PermitRootLogin yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keysad-hoc常用命令
ansible node1 -m shell -a 'echo redhat | passwd --stdin zhangsan'
ansible node1 -m shell -a 'echo "zhangsan ALL=(ALL) ALL" >> /etc/sudoers.d/zhangsan'
ansible node1 -m shell -a 'systemctl stop firewalld'
andible node1 -m shell -a 'setenforce 0'
andible node1 -m shell -a 'sed -i "s/^#Port 22/Port 2222/g" /etc/ssh/sshd_config'
andible node1 -m shell -a 'systemctl restart sshd'
## 检查命令
# 检查是否提权成功
ansible node1 -m shell -a 'id -un' # 查看提权的账号RH442 红帽的Linux性能调优
RH358 服务自动化
CL210 OSP 红帽的云计算平台
CL260 RHCS ceph的云存储
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以邮件至 hjxstart@126.com
